Welcome back! This is week 9 of my GSoC project, and we’re very close to full DOS support for the Dungeon Master engine. Sound is working, graphics are mostly in place — the last remaining issue is corrupted wall graphics, which I’ve been digging into this week.
The Wall Atlas Problem
In the original Amiga version, the Left, Center, and Right walls for a given depth were stitched together into one wide “atlas” image — for example, D3LCR combined all three walls for Depth 3. When drawing, the engine would use an X-offset (srcX) to pick the right piece:
Left Wall (D3L):srcX = 0
Center Wall (D3C): srcX = 61
Right Wall (D3R): offset further right
When the game was ported to DOS, this atlas approach was abandoned. The Left and Right walls became their own standalone, tightly cropped images, and the D3LCR file was repurposed to contain only the Center wall.
This is where things get tricky. The engine’s wall-drawing logic was built around the Amiga’s atlas assumptions — offsets, widths, and memory layouts all baked in for that single-image approach. I’m currently working through exactly how to handle this, and hopefully in 1-2 days the dungeon walls will finally look the way they should.
I’ll try to add another detailed blog covering all the code changes by the end of this week. That’s it for this week — see you in the next one! 👋
Most of a Director game is one movie playing at a time. You leave one, you enter the next, and the engine only ever has a single score ticking over. But Director also lets a cast member be another whole movie (a “movie cast member”, #movie in Lingo) that runs in parallel, inside a sprite, while the host movie keeps going around it. This week I made ScummVM actually do that.
Director’s vocabulary, quickly: a movie is a timeline (its score) of frames. Each frame has numbered channels, and a sprite sitting in a channel is one on-screen instance of a cast member, an asset from the movie’s library. The stage is the window everything draws into, and Lingo is Director’s scripting language.
The thing that forced the issue is the mini-map in Star Trek: TNG Interactive Technical Manual. You walk the decks of the Enterprise-D in a QuickTime VR panorama, and in the corner there’s a little schematic of the deck with a marker showing where you are. That mini-map isn’t a picture the host draws: it’s a separate Director movie, linked in as a cast member, running its own scripts, watching a shared global to know where the marker goes, and setting another global to send you somewhere when you click it. Get movie cast members working and the mini-map comes alive. That was the goal.
By the time the mini-map worked I had three problems on my list that looked entirely unrelated, to each other and to it: the host’s caption text had stopped drawing, the input queue was growing without bound, and DT, the debugger, was flickering between two movies’ scores several times a second. I assumed three bugs. Underneath, they were one.
A cast member that drew nothing
Movie cast members and film loops share the exact same layout on disk. The only real difference is a single flag: a film loop is a canned animation, a movie cast member runs its own Lingo (scriptsEnabled). Because of that shared format, ScummVM already modelled MovieCastMember as a subclass of FilmLoopCastMember, and inherited the film loop’s loader, which looks for an embedded SCVW resource. A movie cast member doesn’t have one. Its content lives in a separate movie file, named in the cast info. So the loader found nothing, and the cast member drew nothing at all.
The first job, then, was a real load(): take the linked path out of the cast info, resolve it with findMoviePath, open the archive, and build a proper Movie out of it that the cast member owns. Point the inherited _score at that movie’s score and suddenly there are frames to draw.
There was also a bug. The moment the linked movie loaded, the whole stage resized itself to the mini-map’s dimensions and the panorama vanished. A movie, when it loads, assumes it owns the stage: it resizes the window, recentres it, repaints the background colour. That’s correct for a movie you open normally, and completely wrong for one living inside a sprite on someone else’s stage.
The fix is a flag, Movie::_isEmbedded, set on the linked movie. Anywhere loadArchive() reaches for the stage, it now checks that flag first and leaves it alone. An embedded movie borrows the host’s window; it never gets to own it. That flag turns out to be load-bearing: it comes back to guard rendering twice more before this is over.
Where a movie cast member sits: it subclasses the film-loop cast member and owns a linked Movie, which points back at the host through _parentMovie.
Running in parallel
Here is the idea that organizes everything below, and it isn’t mine, sev handed it to me at the start: a movie cast member is a Window that doesn’t own a window. A real ScummVM Window has its own current movie, its own execution state, and its own step. A movie cast member needs all three, but it has to borrow them from the host, use them for exactly one step, and give them back. Every fix in this post is a consequence of getting that borrow-and-return right.
Start with the step. Loading a movie is not the same as running one. A film loop is a flipbook: you just ask it for the sprites at frame N. A movie cast member has to step: run its frame scripts, honour go, fire its events, advance. So update() now steps the linked movie’s score exactly like a real movie does.
The word “exactly” hides a decision: how fast does it step? A movie has its own tempo channel, so should the mini-map run at its own tempo, independent of the host? Rather than guess, I built a test movie in Director 4: a host at one tempo with an embedded movie authored at a different one, each incrementing a visible counter, and watched what the original engine did. The counters stayed locked together. Under D4, a movie cast member ignores its own tempo channel entirely and advances once per host frame, no independent clock, no drift. I’ve only verified this for D4; if D5 or D6 differ, that’s the first thing I’d re-check.
Then there’s the question of whose movie is “current”. Almost everything in Lingo resolves against the current movie: go, handler lookup, cast lookup, the clickOn. If the mini-map’s go is going to move the mini-map and not the panorama, the linked movie has to be the current movie while it steps. So update() swaps the window’s current movie to the linked one, steps, and swaps it back. For the duration of one step, the embedded movie is the current movie, and everything in Lingo resolves against it.
Reaching out, and getting on screen
Two things fell out of the borrow that I hadn’t planned for. First, the mini-map’s scripts call handlers that don’t exist in the mini-map: levelblinker lives in the host. And they read cast members that also live in the host. The linked movie isn’t self-contained; it’s written assuming it can reach up into whatever movie loaded it. That gave Movie a second new member, _parentMovie, and handler and cast lookups now fall back to it when the embedded movie comes up empty. The mini-map simply doesn’t run without it.
This fallback makes this title work, and it might be the wrong general answer: Director also has shared and external cast libraries, and a message hierarchy with a specified order, and it’s possible the “authentic” fix for another game is one of those rather than “fall back to whoever loaded me.” I verified that the mini-map needs the parent for levelblinker and its cast lookups; I have not verified that “fall back to the parent” is what Director itself does in general.
One host frame: the host steps the linked movie, which refreshes its own channels; the host then pulls those channels into the sprite through getSubChannels().
Second, getting the embedded movie’s pixels onto the screen. Rendering in ScummVM’s Director engine is pull-based: a window renders the channels of its current movie and nothing else. The embedded movie is never the window’s real current movie (only for that flicker of a step), so it can’t push itself onto the stage. Instead the host pulls: the embedded movie’s own renderFrame() refreshes its channels but, seeing _isEmbedded, stops short of drawing them anywhere, and then getSubChannels() takes those live channels, scales them into the sprite’s bounding box, and composites them. “Live” is the important word: it’s the actual running channels, so anything the mini-map’s scripts change shows up immediately.
Ghost in the corner
With all that in place the mini-map appeared, animated, and tracked my position. And it also drew a second copy of itself, small and wrong, jammed into the top-left corner of the stage.
My first guess was a highlight artifact, something about the sprite’s hilite flag drawing where it shouldn’t, so I tried guarding that. It didn’t help, and I dropped it.
The real cause was the pull-based rule again, from the other side. When the embedded movie stepped and called something that triggered updateStage, it went all the way into Window::render() and rendered its own channels onto the shared window, at the embedded movie’s native origin, which is the top-left of the stage. The composite path was doing its job in the sprite; this was a second, illegitimate path drawing the same content in the wrong place.
The guard I added is at the top of Window::render(): if the current movie is embedded, return immediately. It’s a guard; I’m discarding a render request that should never have travelled this far, rather than modelling what updateStage “should” do for an embedded movie in real Director. For this engine the invariant I want holds either way, an embedded movie reaches the stage through exactly one door, getSubChannels(), and no other. Ghost gone.
Two other things were wrong by this point, and I was ignoring both. Mouse events were piling up in the queue instead of draining. DT was flickering between two scores. Neither seemed connected to anything I’d just done, so I wrote them down and kept going.
Text that wouldn’t draw
The mini-map worked, but a piece of the host broke: the panorama’s description text (the caption that tells you what you’re looking at) stopped drawing. It rendered fine on master. Something in my branch had killed it.
I couldn’t see it by reading, so I bisected (kind of). First across the commit series: build each commit, run it, look for the text. One commit was fine, the next was broken, which pinned it to “run the movie cast member as a parallel movie”. That’s a big commit, so I bisected within it, as a designed ladder of four builds, each enabling one more thing than the last:
don’t step the embedded movie at all, text draws;
start the embedded movie but don’t step it, text draws;
step it, but skip the sprite update, text draws;
step it with frame-script execution, text gone.
The last rung was the one that broke, so the culprit was specific: the embedded movie running its own frame scripts.
The invariant that was violated is small and exact. A Window owns one LingoState: a call stack, plus a stack of frozen states, which is how Director suspends a script mid-run to go do something else. That’s one thread of execution. The mini-map issues a go() on every single frame (that’s how it repositions the marker), and each go() freezes the current state and pushes it onto the window’s frozen stack. Because that stack was shared between the host and the embedded movie, the mini-map’s per-frame freeze kept pushing the host’s own scripts aside, and the script that draws the caption never got to run.
The fix is to stop sharing the one thing that must not be shared. The movie cast member now carries its ownLingoState, and a new Window::swapLingoState() exchanges it onto the window only for the duration of a step, then swaps it back. The mini-map’s go() now freezes the mini-map’s own state and leaves the host’s completely alone.
Before, one shared execution state, so the mini-map’s per-frame freeze blocked the host’s scripts. After, one state per movie, with the host’s left untouched.
Then the other two symptoms went quiet, and it took me a moment to see why, because they weren’t fixed by identical means.
The input queue drains only when the window isn’t mid-jump: in Score::step() the drain is gated on !hasJump and an empty frozen stack. With one shared frozen stack, the mini-map’s per-frame go() left the window permanently mid-jump, so the host’s routed mouse events had no frame in which they were allowed to drain. Isolating the state means the host is never mid-jump on the mini-map’s behalf; and because the mini-map is always mid-jump on its own behalf, update() drains its routed clicks explicitly, once per step. Same root cause, two coordinated fixes.
DT was flickering because it samples the window’s live Lingo state once per frame, and with a single shared state it had a real chance of sampling while the embedded movie owned it. The current-movie swap is still there, so DT can still land inside a step, but it now reads a state that belongs unambiguously to one movie instead of a half-updated shared one, and in practice the flicker is gone. I’d call this one strongly suspected rather than proven.
One shared LingoState; three symptoms.
Shared globals, private minds
It would be easy to conclude from all that the two movies should be walled off completely. They shouldn’t, and the mini-map is exactly why. Its whole job is a conversation with the host through shared globals: it reads gNodeNow to know where to put the marker, and writes gNewNode when you click to ask the host to travel. Wall the globals off and that conversation becomes impossible.
So the line to draw is between two things that get lumped together as “state”. Global variables stay shared: they live on Lingo, one table, host and embedded both reading and writing it; that’s the communication channel. Execution state (the call stack, the frozen stack, where each movie is in its own scripts) is private, one per movie.
Globals stay shared on Lingo; execution state is swapped per movie, one LingoState at a time on the window.
A click, end to end
The click is the whole design in one path, because it crosses the host/embedded boundary twice and the only things that cross with it are two globals. The diagram below traces all seven steps; the part worth saying in prose is the shape. Your click is hit-tested by the host, routed into the mini-map (with the bounding-box scaling inverted so the coordinates land in its own space), and handled by its on mouseUp as set gNewNode to the clickOn - 10 (the clickOn is the clicked sprite’s channel number; the - 10 is the mini-map’s own offset from channel to node id). From there it’s globals only: the host reads gNewNode, navigates, and writes gNodeNow; on its next exitFrame the mini-map reads gNodeNow and moves the marker. Two globals cross the boundary; everything else stays on its own side.
A click crosses the boundary twice; only gNewNode and gNodeNow cross with it.
Loose ends
A handful of things I closed, verified, or explicitly left open:
scriptsEnabled. The flag this all started with was decoded but never enforced, so a movie cast member always ran its Lingo. It’s now honoured: with scripts off, the linked movie is a passive flipbook. The lever already existed as Score::_haveInteractivity, which gates every event, frame scripts included, while a frame still advances underneath it, so the movie’s frames and channels update but no Lingo runs and it doesn’t respond to the mouse.
Blast radius of the hit-test change.Sprite::respondsToMouse() now returns true for a movie cast member (when its scripts are enabled). That’s an engine-wide function, but the change only adds a branch for kCastMovie; every other cast type takes the same path as before, so no other game’s click behaviour moves.
Regressions. These changes touch shared render and hit-test paths, so the check that matters is the engine’s D4 unit-test suite: it still passes at its baseline (196 pass, 11 pre-existing failures), unchanged from master. But there are places tests don’t cover.
Untested corners. One movie cast member on stage, single instance, is what I ran. Two at once, and a movie cast member nested inside a linked movie, are both things Director allows and I haven’t tested; the state swap is a two-slot exchange, and a robust version is probably a push/pop. I also haven’t profiled the per-frame cost of stepping a second score, though with one embedded movie it isn’t perceptible.
Moving in the panorama doesn’t move the map. Clicking the map navigates the panorama, but walking through the panorama doesn’t move the marker. The map is a pure consumer of gNodeNow, and the host only updates gNodeNow from its QTVR node-change path, so this is a QTVR-side gap, not a moviecast member one.
Where this is headed
Next up is the DT side, so the next person to open a movie cast member can watch both scores at once. None of the debugging above was done with a nice tool: it was rebuild-and-observe and reading the call graph, and DT itself was one of the broken things. Which is exactly the gap I want to close, and why this line from Zig’s creator Andrew Kelley (link to the quote) is the note I want to end on:
I needed to code up a simulation, I needed some visualization, I needed more introspection, I needed a way to understand what is happening, so that debugging wasn’t an all-day affair where I was using command line tools, but debugging could look like just looking at an animated graphic of what’s happening and just spotting the obvious problem and fixing it immediately.
When you have the right simulation, that’s what you can do. When your system is accessible, bugs are trivial.
It’s seven commits, building from reading the flag word correctly, through loading and playing the linked movie, to running it in parallel and finally isolating the Lingo state.
Welcome back, the CgBI decoder is up and loading the assets wonderfully, see-
I am currently rendering text on it which is too close to be completed too. The text is rendered like this
I have already ported the required infrastructure for the hint system that includes methods like setSeenScreen and hasSeenScreen which, as their names suggest, sets the screen to true and tells if the screen is set respectively. It tracks that using a boolean array _seenScreen. Similar methods and array are there for the hint answers too. The hint lookup table is almost completed too. You’ll see that in the next blog.
Once the hint system gets implemented, I will most likely be moving to the implementation of the intro and outro videos. After that, I’ll implement the audio.
There’s hotspost too which is yet to be implemented. So, I’ll have to do that too. See you next week.
After last week’s big push to get Chamber of the Sci-Mutant Priestess over the finish line, this week was all about MacVenture — turning last week’s “the games boot!” moment into something people can actually install and play.
Getting the games out of Steam
The biggest chunk of work went into the tooling. Last week I explained the awkward situation with the Steam releases: the actual game data isn’t sitting there as loose files, it’s a Mac HFS disk image buried inside a Chromium wrapper executable. Extracting that by hand once, for debugging, is one thing — but nobody buying the games on Steam should have to do that.
So I taught ScummVM’s dumper-companion how to do it. Point it at the Steam .exe, and it now digs the HFS disk image out of the PE resource, punycodes the filenames so they survive on a non-Mac filesystem, and hands you a clean set of game data. What used to be a fragile manual ritual is now a single command.
The Apple IIGS rabbit hole
While I was in there, I noticed the Steam executables actually carry two disk images — the Mac one everybody expects, and an Apple IIGS version tucked away in a separate resource. The IIGS releases have their own look and feel, so it felt wrong to leave them on the table.
Two problems stood in the way. First, the dumper only knew about the Mac disk, so I extended it to pull the IIGS .2mg image as well. Second — and this was the more surprising one — ScummVM’s detection for the IIGS games was quietly dead. The detection entries existed, but there was no data-fork fallback, so the files these games actually ship with never matched anything. I fixed the detection so it hashes the right fork, and suddenly the IIGS versions light up in the launcher like they always should have.
A detour back to Chamber
One small but satisfying fix landed on the Chamber side too. A user reported (bug #17004) that if you had both the CGA and EGA data in the same folder, the engine would stubbornly force CGA regardless of what you picked. It turned out to be a detection-hint issue, and now the engine honors the variant you actually chose.
Testing begins
With the tooling in place, I’ve started the part I’ve been looking forward to: real playthroughs. Déjà Vu is first up — the noir detective one, the natural place to start — and so far it’s going really well. The window manager behaves, items drag and drop where they should, the text scrolls cleanly. No showstoppers yet, which is exactly what you want to see from the first of four games.
Next week
The plan is to keep grinding through the playthroughs — finish Déjà Vu, then move on to Déjà Vu II, Uninvited, and Shadowgate — noting anything that misbehaves along the way. If they hold up like Déjà Vu has, the goal is to get MacVenture’s Steam and IIGS releases marked as testing so players can start reporting back.
As always, thanks to my mentors for the steady guidance — onward to the testing grind!
Hello and welcome back! This week I worked on the DOS version of the Dungeon Master engine, and a big part of that was getting the VGA colors right, since the DOS release used 256-color VGA graphics.
I added DOS-specific palette index constants to the graphics header, letting the engine track different environment levels, menus, and spell fade states. With the correct colors generated, I hooked them up directly to ScummVM’s palette manager, enabling accurate rendering and smooth screen fades.
The palette changes depending on whether the game is running normally, paused, or displaying the inventory screen. I implemented this switching in drawViewport() — accessing the inventory switches to the inventory palette, while drawing the dungeon uses the active environment palette.
Light levels also affect how bright the viewport is, from pitch black to fully lit. I updated the palette loading logic to read light levels directly from the runtime viewport palette _palDungeonView.
Next, I updated the startEndFadeToPalette method. In the original game, whenever the screen needs to change — opening the main menu, starting the game, entering a new area — the engine calls a transition function with a raw buffer of color data. On the Amiga, it would manually fade color-by-color. On DOS however, screens are displayed using the pre-defined full VGA palettes set up earlier.
So the matching logic looks at the incoming color buffer and figures out which game screen it corresponds to — is it blank black, the intro, the credits, or the main dungeon view? Once identified, the correct DOS VGA palette is applied immediately.
The DOS version organizes its wall and floor graphics quite differently from the Amiga version. On DOS, wall sets are much larger — 40 graphics per set — starting at index 86, with floor/ceiling sets beginning at index 78.
The indices are spread out differently, to address which I added platform checks to load the correct offsets throughout. Memory allocation for all environmental graphic buffers — D1/D2/D3 walls, door frames — was also adjusted to dynamically compute sizes and locations using the correct platform-specific layout.
The IMG3 Decompressor
With the VGA color systems and palette tables fully in place, the final step to getting graphics on screen was writing the decompressor for the DOS version’s custom image format.
The DOS release compresses its graphic assets using the IMG3 RLE format, which differs significantly from the byte-oriented IMG2 format used on Amiga. I integrated an IMG3 decoder into loadIntoBitmap().
DOS bitmaps also require every row of decompressed data to align to an even byte width. For odd-width graphics, the decompressor needs to inject a padding pixel at the end of each line. I added row wrapping, ensuring the decompressed output aligns correctly.
Once the decompressor was running, we needed to make sure the game allocated enough memory for the decompressed graphics. Since the DOS decompressor pads odd-width graphics to even byte boundaries, I updated the memory allocation routines for all game assets, replacing standard pixel-width lookups with a new getDecompressedWidth() function that returns the even-aligned width for DOS, preventing memory corruption when loading graphics.
With all these changes in place, the DOS version now looks like this:
Corrupted Graphics — What’s Left
The graphics are still corrupted due to two root causes (hopefully 🙃):
First, DOS has more database entries than Amiga, so all the hardcoded Amiga constants are pointing to the wrong data. The font, item icons, creatures, and pit/ceiling graphics are all shifted on DOS, meaning the engine is currently reading from the wrong indices entirely.
Second, unpackGraphics() stops unpacking at index 532 — the Amiga limit — but DOS graphics continue up to 670, with sounds starting at 671. This leaves the font and item graphics completely uninitialized in memory.
These are what I’ll be focusing on next week, with the goal of bringing the DOS version to a fully playable state as soon as possible. That was it for this week — see you in the next one! 👋
The ScummVM Team is pleased to announce that Chamber of the Sci-Mutant Priestess — originally released in Europe as KULT: The Temple of Flying Saucers — is ready for public testing!
Step into the boots of Raven, a young man gifted with psychic powers, held prisoner deep inside the temple of an alien priestess. His companion, Sci-Fi, has been captured too, and to reach her, Raven must survive the five Ordeals that stand between him and the Chamber. Wits alone will not be enough: you will need to master eight distinct psi-powers, from the humble Solar Eyes to the brutal Extreme Violence, to outsmart the strange creatures of this surreal, post-apocalyptic world.
Originally developed in 1989 by the French label Exxos (ERE Informatique), with an art direction inspired by illustrator Philippe Caza, KULT is a genuine cult classic of European adventure gaming, remembered for its dreamlike atmosphere and its unusual, power-driven puzzles.
For this testing period, ScummVM supports the DOS versions — with CGA, EGA and Hercules renderers, playable in English, French and German — as well as the Amiga releases. The engine was reverse-engineered by bambarbee and brought into ScummVM during Google Summer of Code.
As usual, you will need the original game data files to play. To join the test, grab a recent daily development build, add your game directory to ScummVM, and play through the game. Please report any problems you encounter on our issue tracker, following our bug submission guidelines. Screenshots and saved games demonstrating an issue are always helpful.
Back to a normal week after the midterm. It split cleanly in two: the first half closing out the debugger work I’d been carrying for a while, and the second half falling down a rabbit hole about film loops that I’m still in.
Closing out the debugger
The two fixes I said were nearly done last week both landed, along with a third that had been sitting on my “still on the list” note: the channel visibility toggle that did nothing while the movie was paused.
That one turned out to be a nice little bug. The debugger keeps a _windowToRedraw request, and it was being serviced inside onImGuiRender(), which runs after the frame has already been composited. During normal playback you never notice, because the next frame comes along a few milliseconds later and picks up the change. But when the movie is paused, there is no next frame. The request sat there and was serviced into a frame that had already been drawn, so the toggle appeared to do nothing at all. Draining the request in the main loop beforedraw() means it composites into the same frame, and the toggle works while paused.
I also gave the Cast window some overdue navigation help: a serial column in the list view, a toggle that overlays the member number on each tile in grid view, and a member count in the toolbar that shows shown/total when a filter is active. Small things, but this window is where you spend most of your time when a game’s cast is a thousand members long.
A different film loop bug
I wrote about film loops two weeks ago, but that was about where they get drawn, the registration point problem. This week’s bug is about when they move, and it turned out to be a much more interesting question.
The code that drives them is a single function, Score::incrementFilmLoops(). Every render tick it walks the channels, and for each one holding a film loop it bumps that channel’s frame counter by one. Simple, and mostly right, a film loop has no tempo of its own, so it animates in lockstep with the score that hosts it.
The problem is the “every render tick” part. It advanced regardless of what the playhead was actually doing. So a film loop kept animating while the movie was paused, and it kept animating while the playhead sat looping on a single frame. I had a suspicion both were wrong, but a suspicion isn’t a bug report.
Reading the manual
The books are the fastest way to settle these questions, except the ones I have are scans of 1990s manuals, and the OCR is rough. Searching a 670-page PDF for “film loop” returns nothing, not because the phrase isn’t there but because the OCR has rendered it as film loop, filmloop, film ]oop, and about six other things, with stray punctuation and line breaks landing in the middle of words.
sev pointed out the obvious thing I’d been ignoring; these books have indexes, and the index is a better entry point than search a lot of times.
That got me to the answer: film loops animate in step with the movie’s playback head. If the playback head isn’t moving, neither is the film loop. Director in a Nutshell (Epstein, 1999).
Asking the original
Books are good, but the actual application is better, so I built small test movies in real Director 4 and Director 5 to check each case directly. This is where it stopped being a one-line fix.
Pausing behaved as the book describes, the film loop freezes. ScummVM animated straight through it. Clear bug, and it applies to every version.
go the frame, a script that loops the playhead on a single frame, split by version. Director 4 freezes the film loop. Director 5 animates it. So this one needs a version check, not a blanket fix, and if I’d only tested in D5 I would have concluded there was no bug at all.
The tempo channel, a frame that waits a set number of seconds, was the interesting one, because ScummVM already gets it right, by accident of structure rather than by design. When the score is waiting on a tempo, isWaitingForNextFrame() returns early and renderFrame() never runs, so incrementFilmLoops() never gets called and the film loop freezes on its own. So no “fixing” here.
The fix, and checking it didn’t break anything
The change was pretty small, an early return when playback is paused, and a version gated check that tracks the last frame number the film loops were advanced on, so a playhead looping in place doesn’t count as movement in D4.
The part I want to note is the verification, because “small change” and “safe change” are not the same claim. The director-tests repo has a regression suite that runs a few hundred Lingo assertions across a stack of test movies. I ran it against my build: 196 pass, 11 fail. That number alone tells you nothing, you need to know what it was before.
So I checked out the parent commit, rebuilt clean master, and ran the identical suite: 196 pass, 11 fail, and the failing assertions were byte-identical once sorted. All eleven are pre-existing failures in event and play tests, none of which involve film loops.
That’s the difference between “I think this is fine” and “this changes nothing else,” and it’s the version I can put in a commit message.
Archaeology: this was tried once already
The reason I care about the film loop code is that it’s the foundation for the thing I’m working on now, movie cast members, which are Director’s way of embedding a whole linked movie as a single sprite. Where a film loop is inert animation, a movie cast member keeps its own scripts and sound. ScummVM’s MovieCastMember currently inherits from FilmLoopCastMember and overrides almost nothing, so today it renders as a silent, non-interactive animation and the flag that says “run this movie’s scripts” is parsed and then ignored.
Before starting I went looking for prior art and found sev had a director-moviecast branch. It took a while to work out what happened to it, because the merge base pointed somewhere confusing, the answer is that it was merged and then reverted. The revert message is the useful part: the approach drove the embedded movie by calling step() on its score, which was gated by _nextFrameTime and had unsafe side effects, including resetting video playback. It fixed a walking animation in Mission to Planet X and broke other things.
sev’s view is that movie casts need rewriting from scratch on the film loop approach, and having read the revert I understand why. Knowing exactly where the previous attempt hit the rocks is worth more than a clean slate.
Still on the list
Starting the rewrite itself. The design question I’ve been chewing on is how an embedded movie “runs at the same time” as the movie hosting it, and the answer is that it doesn’t, not in the way the phrase suggests. Director’s concurrency is cooperative, the main loop steps the stage’s score one tick, steps each open window’s score one tick, and composites once. Nothing runs in parallel; everything is interleaved on a single thread, and the deterministic ordering that gives you is a feature, because scripts fire at defined frame boundaries.
Tempo works the same way, as a clock rather than a counter: each score records the wall-clock time its next frame is due, and holds its current frame until that time arrives. Two scores at different tempos coexist because each gates on its own deadline. So an embedded movie doesn’t need a thread and doesn’t need to skip frames, it needs its own deadline, and one step per tick when that deadline comes due.
So after I discuss further with sev and have a solid plan of what to do, I’ll start the coding.
Gus Updates??
Gus Goes to The Kooky Carnival is now bug-free (from my testing). Once sev green lights it, it will be put into release. Other than that I am shifting my focus to movie cast members, away from gus games. for now.
As I mentioned in the last week’s blog, the game assets have CgBI PNGs in it which we need to decode.
Initially, I thought about converting it to a standard PNG to have the PNGDecoder decode it but since we have the raw pixels extracted, we can just draw the surface.
How different is the CgBI format than standard PNG
Apple had created this format to optimize for the native pixel format of the iPhone’s early PowerVR GPUs. It contains significant differences like-
An extra critical chunk(CgBI) – Right after the 8 byte standard PNG header and 4 bytes for length, CgBI format has also a CgBI type field from bytes 12-15.
Swapped pixel format – Instead of a standard PNG file’s pixel format, i.e., RGBA, CgBI format has the pixel format swapped to BGRA. The red and the blue channel are swapped, presumably for high speed direct blitting to the framebuffer.
It contains raw deflate data. It has the zlib header, footer removed from the IDAT chunk.
It has every channel pre-multiplied with the alpha channel.
Pre-multiplied with the alpha channel during encoding: color’ = color * alpha / 255
I have extracted the raw pixels by removing the CgBI header, un-premultiplying the alpha channel and swapping the red and blue channel all while working on raw deflate data. Next, I will be drawing the surface and we’ll have the help window displayed on our screen. The immediate next step after that would be to render the help contents on it. Hopefully, I will be briefing about that in the next blog 😉
Last week I was still deep in the reverse-engineering weeds of the Amiga port. This week the mood changed completely: it was the week Chamber of the Sci-Mutant Priestess finally stepped out into the light, and the week I started the work on a second engine called MacVenture.
Chamber goes to testing
The headline first: Chamber is now enabled for the upcoming ScummVM release and marked as testing. After all the months of decoding scripts, chasing endianness bugs, and rebuilding renderers one palette at a time, it felt genuinely strange to finally flip the switch.
The change enables the engine to build by default and promotes all five game variants — the multi-language CGA build, the US CGA build, the EGA build, and both Amiga builds (EU and US) — from ADGF_UNSTABLE to ADGF_TESTING. That last part matters: it means the games now show up for players who want to try them and report issues, instead of being hidden behind a developer flag.
It also carried a couple of last-minute fixes I wanted in before the release:
The endgame saucer animation was accumulating frames on the linear back buffer in EGA and Amiga modes, leaving a smeared trail instead of a clean animation. Fixed.
Hercules mode mouse mapping was off, so hotspot detection didn’t line up with what you saw on screen. Corrected the coordinate mapping.
And, on a more personal note, my name went into the credits with this work. Small thing on a diff, big thing for me.
A second engine: the MacVenture Steam versions
With Chamber wrapped up for release, my mentor pointed me at the next target: getting the MacVenture games — Shadowgate, Déjà Vu, Déjà Vu II, and Uninvited — running from their Steam releases, so we can eventually announce those for testing too, exactly like we just did with Chamber.
I expected to spend the week playing games. Instead I spent the first part of it doing detective work, because the Steam builds are not what you’d think.
Where is the game?
Each Steam download is basically a small Chromium (CEF) web wrapper: a .exe and a few DLLs. There are no loose game files anywhere. It turns out these are the “MacVenture Series” web ports, and the actual game data — the original Macintosh files, resource forks and all — is stored as an 800K Mac HFS disk image embedded as a resource inside the .exe.
So the pipeline to feed ScummVM became:
Pull the disk image (.dsk) out of the PE resources in the executable.
Run it through ScummVM’s own dumper-companion tool, which extracts the Mac files and, crucially, punyencodes the filenames. That’s the part that lets a name like Déjà Vu survive as xn--Dj Vu-sqa5d on a normal filesystem while ScummVM still recognizes it.
The nice surprise: once extracted, all four games were detected immediately as the existing “1993 rerelease” entries — the resource forks are identical — so no detection work was needed at all.
The crash that blocked everything
The bad surprise: all four games crashed on startup with an assertion failure the moment the GUI tried to initialize.
This one was a proper rabbit hole, and a good reminder of how far an uninitialized value can travel before it hurts you. Tracing it back through the window manager and the nine-patch border renderer, the story was:
MacVenture builds its window border offsets in borderOffsets(), setting every field of the BorderOffsets struct explicitly… except a newer field, titlePadding, which was never assigned.
That garbage value fed straight into the console window’s title width calculation.
In nine_patch.cpp, the border width is computed as dw = _h._fix + _titleWidth. With a garbage title width of ~32,800, dw overflowed to 32,864.
That produced an invalid Common::Rect (its right edge wrapped past its left edge), which tripped the assertion and aborted the game.
The fix is a single line — initialize titlePadding to 0 alongside the other offsets — but finding it meant instrumenting the whole border-drawing path to watch the bad number appear. And because it’s a genuine upstream bug, the fix helps the ordinary 1993 rereleases too, not just the Steam ones.
After that, all four games boot and run cleanly.
Reflection and what’s next
Two milestones in one week: Chamber crossing the finish line into testing, and MacVenture going from “won’t even start” to “boots all four games.” I owe a big thank-you to my mentor, sev, for all the help and patience.
Next week is the fun part I thought I’d be doing this week: actual playthroughs of all four MacVenture games. I’ll be watching closely for the Window Manager quirks, the lasso/marquee item selection, and the console text scrolling — the areas most likely to still hide bugs. Once those hold up, we’ll document the extraction steps and announce MacVenture for testing as well.
The trail leads onward! It's time once again to step into Nancy's shoes and follow the clues... We are pleased to announce that ScummVM now supports two more titles from the long-running Nancy Drew adventure game series.
In Nancy Drew: The Secret of Shadow Ranch, the famous teenage detective trades city sleuthing for a vacation out west at a real western-style ranch — but her getaway turns into a mystery when the ghost of the ranch's former owner comes riding in on his ghostly horse. Before long, Nancy finds herself caught in the middle of a dangerous and vengeful plot. Is the phantom rider real, or is someone with very earthly motives behind it all?
In Nancy Drew: Curse of Blackmoor Manor, Nancy is summoned across the Atlantic to a 14th-century castle deep in the spooky British moors, home to the Penvellyn family for centuries. The manor's newest resident, a new bride named Linda Penvellyn, has locked herself away in total fear, refusing to see or speak to anyone. Has the mansion been cursed? Has the spirit of the "old witch" returned? Or is something else entirely going on? It's up to you to find out.
As usual, you will need the original game data files to play these games. The games are available for purchase through HeR Interactive's website or Steam. To play them with ScummVM, you will need a daily development build. If you encounter any issues, please submit a bug report to our issue tracker, following our bug submission guidelines.
Quick update this week. I didn’t get as much done as usual, life got in the way a bit, but there was still some progress worth writing about.
The big news first
I passed the GSoC midterm evaluation! Halfway through the program now, and it feels good to have the first half officially signed off.
Most of my work this week went into the visual debugger for the Director engine. A while ago I did a deep audit of the debugger code, going file by file and noting down everything that looked wrong, from crashes to small UI annoyances.
This week that work landed upstream as a set of thirteen commits. Among other things, it fixed several crashes when switching movies with debugger windows open, a memory leak in the Score window, breakpoint toggles that only worked on the first row, cast members that were silently missing from the Cast window filters, and a bunch of windows that could not tell you which movie they were looking at.
It also added a couple of small features, like being able to open a sprite’s behavior script directly from the Score window.
After the merge, sev tested the debugger against real games and reported a fresh batch of issues, which is what I am working on now.
Two fixes are almost ready: one makes the call stack in the Execution Context properly show where execution sits in each handler when you click through the stack frames.
The other fixes the Cast window, which could show an empty details panel for some cast members and stopped rendering its list partway through on games with very large casts, like Jewels of the Oracle.
Still on the list
The channel visibility toggle does not take effect while the movie is paused, so that is next up.
That’s it for this week. Shorter update than usual. See you in the next one.
Hi everyone, this is Week 7 of GSoC, and I’m happy to share that I’ve successfully passed the midterm evaluation 😃. As I told you in the last blog, the Amiga version of Dungeon Master is now fully playable — so we’ve decided to extend support to the DOS version as well.
I began by analysing the DOS version and found that most of the game logic is the same across both platforms. I started by adding the detection entry for the DOS English version, then added Little-Endian support in the asset loaders of the engine.
There were also differences in the graphics file format — the DOS version uses version 3.x, which has a special 2-byte signature at the start of the file to identify it as such. I added support for detecting this signature by reading the first 2 bytes of the file as a header word and checking if it has 0x8000 set, which identifies it as version 3.x, and adjusted the table start offset and bytes-per-graphic accordingly so the loader handles both formats correctly.
Sev gave me access to Coverity’s static analysis and pointed me to the issues flagged for the DM engine. I went through them one by one and found that most were false positives.
Things like null pointer dereferences or out-of-bounds accesses that Coverity flagged were in practice guarded by earlier logic in the engine — the problematic paths simply couldn’t be reached during normal execution. For those, I silenced the warnings.
A handful of the issues were genuine, and I fixed those properly.
My college has started and I had to travel back to my hostel from my hometown, so progress was a bit slow this week. I’ll make up for it this week by quickly wrapping up the remaining Coverity issues and getting back to work on the DOS version.
That’s it for this week. See you in the next one! 👋
We are past the mid-term now which means half of the GSoC season has come to an end and we have started on the second half. I overlayed the “Options” icon and the “Help” icon.
The wrench is for the “Options” that’s essentially the control panel and the help icon is for the hint system. It has a bunch of questions depending upon the part of the game we are in and a few hints for that question.
For an example –
Q – The Firedoor is locked – how do I open it?
A – Get the rung from the top of the stairs on the left of the gantry.
Open your inventory and use the rung on the fire door to lever it open.
The original source code uses a huge switch block to map the questions to the answers. I will be taking the same approach when I implement the text in ScummVM.
So, we load the help window and render the text on it.
But another challenge comes just at that point. The game assets are not standard PNG files but rather, a non standard variation of the PNG format optimized by Apple for iOS devices. It is called the CgBI format.
Since we depend upon libpng to decode our PNG files, CgBI files cannot be decoded since libpng doesn’t support them. To tackle this issue, we have decided to write a CgBI to standard PNG converter. We already have a program to do that which was shared by my mentor, @DJWillis.
I am currently studying it to understand how it’s doing it since I have a very limited experience in decoding.
Once I understand it, I will port it to ScummVM in the image/ directory where all the other image format decoders live, so that it can also be used in the future for any other games if needed.
After we have the decoder and we load the empty help window, we will proceed with adding the text.
Hello, everyone! With both the European and US Amiga releases of Kult / Chamber of the Sci-Mutant Priestess playable from start to finish, this week I shifted focus from adding features to hardening what was already there. Last week I mentioned that ScummVM runs the engine through the Coverity and PVS-Studio static analysers, and that their reports had turned up a handful of issues worth looking at. This week I went through those reports properly, and on top of that I chased down a save/load bug that had been quietly breaking a couple of rooms after loading a game.
Working through the Coverity report
Static analysers are good at spotting the kind of code that is technically wrong but rarely bites in day-to-day play: unreachable branches, resources that are allocated but never freed, and fields that are read before they are written. Chamber is a reimplementation of a 1989 DOS game, so a lot of the code mirrors the original binary very closely — which means some of these findings are actually faithful reproductions of dead code that was already dead in the original.
That distinction mattered while reviewing the reports, because I did not want to “fix” something that was deliberately mirroring the disassembly. So for each finding I went back to the original code to confirm what was really going on before touching anything.
A few of the more interesting ones:
In CMD_21_VortTalk, Coverity flagged a branch guarded by rand_value >= 170 as unreachable. Checking the disassembly, the num == 7 case it belonged to is dead in the original too, so the branch could go.
In drawRoomStatics, there was a door check for index == 91, but by the time that code runs the index is already constrained to the 50..60 range, so the check can never be true.
In the CGA blitter, blitToScreen had an endY > 200 clamp that could never fire, because dy and h are hardcoded to 0 and 200 just above it.
Alongside the dead code, the report caught two genuinely useful things: a memory leak and an uninitialised field. Several call sites were calling loadFond / ega_loadFond / loadSplash, which return a Graphics::Surface, and then throwing that surface away without freeing it — a small leak every time a room background or splash was loaded. And the engine’s _speaker member was not being initialised in the constructor. Both are the sort of thing that is easy to miss by eye and exactly what these tools are for.
Working through the PVS-Studio report
PVS-Studio leans towards a different class of finding — dead stores and redundant expressions — and it caught a similar mix:
Another impossible clamp in the CGA blitter, this time endX_bytes > 80 on the horizontal axis, again dead because the width is hardcoded to a full 320 pixels.
A dead ofs++ in cga_ZoomInplace, immediately followed by ofs being reassigned to oofs, so the increment never had any effect.
In SCR_23_HidePortrait, a left/right button branch where both arms were identical — this handler simply has no special behaviour to skip, so the branch collapsed to a single path.
In SCR_46_DeProfundisLowerHook, the return value of getPuzzlSprite() was being stored into sprofs and then overwritten on the very next line, so the first store was pointless.
There were also a couple of intentional busy-wait loops that PVS-Studio flagged for having an empty ; body. These are genuinely meant to be empty — they are timing delays — so instead of silencing the warning I gave them an explicit {} body to make the intent obvious to both the analyser and the next person reading the code.
None of these are dramatic bugs, but clearing them keeps the engine’s future reports clean, so real regressions do not get lost in a wall of pre-existing noise.
Fixing room state that vanished after loading a save
The most interesting problem this week was not a static-analysis finding at all — it was a save/load bug I ran into while testing.
Chamber builds each room from a base decor, but scripts frequently draw persistent changes on top of that: alternate decor sets, extra objects that appear once triggered, and the final frames of animations. The catch is that they draw these directly into the backbuffer. On a fresh visit that is fine, but when you saved and reloaded, the engine rebuilt the room from the base decor only — so anything a script had painted into the backbuffer was simply gone.
In practice this meant that things like the De Profundis monster, or Deilos, would fail to reappear after loading a game, even though the game state said they should be there. The state was correct; the pixels that represented it had never been saved.
The fix was to bump the save version to 2 and store what was actually missing: the zone palette, the current video mode, and the backbuffer contents themselves. On load, if the video mode matches, the backbuffer is restored verbatim; otherwise the engine falls back to the old rebuild-from-decor behaviour, so older saves and cross-mode loads still work. While I was in there I also made load reapply the room palette and honour the launcher’s save-slot option, so booting straight into a save from the launcher lands you in a correctly coloured room.
Looking ahead
That wraps up the cleanup pass I wanted to do before moving on. The engine is now noticeably tidier and more robust, which is a perfect state to leave it in. Starting next week, I will be shifting my focus to a completely different engine. I wonder if anyone can guess which one it will be?(Hint: It will be a great adventure!) Stay tuned, and thanks for reading.
The ScummVM Team is pleased to announce that Dracula: Resurrection and Dracula 2: The Last Sanctuary are ready for public testing!
Follow Jonathan Harker through Transylvania and London as he searches for Mina and attempts to put an end to Count Dracula once and for all. Explore panoramic locations, solve puzzles, gather useful objects, and try to survive the Count’s return.
For this testing period, ScummVM supports the original Windows versions of both games through the new PhoenixVR engine. The English, French, and Italian releases of Dracula: Resurrection are supported, along with the English release of Dracula 2: The Last Sanctuary.
The compatible versions can also be found in the Dracula Trilogy release available from GOG.com. The newer Steam releases use different game data and are not supported.
From Spain to Egypt, from Italy to Russia - follow the adventures of T.I.A agents Mort and Phil on secret missions around the world!
Less than a year ago we added Mortadelo y Filemón: Aventura de Cine Edición Especial to ScummVM. Now we can announce that the nine other games based on the same engine can be played using the daily build.
These games were always developed in sets of three: two single-chapter games and a combined game with an exclusive final chapter.
Mortadelo y Filemón: Una Aventura de Cine Edición Original (2000)
Mortadelo y Filemón: Dos vaqueros chapuceros
Mortadelo y Filemón: Terror, Espanto y Pavor
Mortadelo y Filemón: La Sexta Secta (2001)
Mortadelo y Filemón: Operación Moscú
Mortadelo y Filemón: El Escarabajo de Cleopatra
Mortadelo y Filemón: La Banda de Corvino (2003)
Mortadelo y Filemón: Balones y Patadones
Mortadelo y Filemón: Mamelucos a la Romana
While Operación Moscú got a text translation in the English Steam release, the other games are currently only available in Spanish.
Before you start your test run, please read through our testing
guidelines and take some screenshots along the way.
When you fix a bug in a normal program, you fire up gdb or lldb, set a breakpoint, and step through the code. But what do you do when the “program” is a Macromedia Director game from 1995, written in a scripting language whose interpreter died two decades ago?
You build your own debugger. This post is a tour of DT (debugtools), the ImGui-based visual debugger built into ScummVM’s Director engine, which I have been working on since February.
DT was started by other ScummVM developers before I arrived; my work has been rebuilding the Score window, adding several new windows, and hardening the whole thing. Consider this the companion piece to my weekly posts, the missing chapter about where all the “DT:” commits actually go, with the parts I built called out along the way.
Why a game engine needs its own debugger
ScummVM’s Director engine is a reimplementation of the Macromedia Director runtime. Director games are “movies”: a timeline (the score) full of sprites, backed by a library of assets (the cast), all glued together with scripts written in Lingo.
When a game misbehaves, the bug is usually not in ScummVM’s C++ but in the interaction between the game’s Lingo scripts and our reimplementation of Director’s behavior i.e it’s a behavior difference which can be fixed in the C++ code.
But, a C++ debugger can’t help much there. What you actually want to see is: what frame is the movie on, which sprites are on which channels, what script is executing, what are the Lingo variables, and what did the original Director do differently.
DT answers those questions. It runs inside ScummVM itself, drawn with Dear ImGui, and you get it by launching any Director game with --debugflags=imgui. The game keeps running in its window while the debugger windows float around it, live.
This is the debugger layout I currently use. Layouts can be saved / loaded by clicking view > save state / load state.
The white outlines you see around the objects is enabled using the draw all command in the console debugger (see immediately below).
The older sibling: the console debugger
DT is not the engine’s first debugger. One directory up, in engines/director/debugger.cpp, lives the classic console debugger: a gdb-style text prompt (it literally greets you with lingo)) reachable through ScummVM’s debug console. It speaks the vocabulary you would expect, bpset, step, next, finish, bt for backtraces, disasm for bytecode, plus Director-specific commands like channels, cast, and markers, and even a small Lingo REPL for evaluating expressions against the running movie.
The two debuggers are complementary rather than competing. They share the same underlying machinery, breakpoints set in one are visible in the other, and the same interpreter hooks drive stepping in both. The console is precise and scriptable; DT is spatial.
The architecture in one diagram
The whole debugger lives in engines/director/debugger/, about 8,600 lines across a dozen files, and follows a simple shape. debugtools.cpp is the orchestrator: it owns the ImGui entry point, and every frame it calls a show*() function for each window. dt-internal.h holds the shared debugger state, one big struct that remembers which windows are open, what is selected, cached textures, script history, themes, and so on. Each dt-*.cpp file is one window, and each window reads directly from the live engine objects: the current movie, its score, its casts, the Lingo state.
what data is sent where
Because ImGui is an immediate-mode UI, there is no retained widget tree. Every single frame, each window re-reads the engine data and redraws itself from scratch. That sounds wasteful but it is exactly what makes the debugger feel “live”: whatever the engine is doing right now is what you see, with no synchronization layer in between.
The Score window
This was my first big project, and it is still my favorite. The score is Director’s timeline: a grid where rows are channels and columns are frames, and each cell says which cast member is on that channel at that frame. The original Director authoring tool had a famous score window, and game logic constantly jumps around the timeline, so you really want to see it.
The first version of the window was a plain ImGui table. It worked, but it could not look like Director’s score, and it fought the framework on things like custom cell decorations. So I rewrote it using ImGui draw lists, which are essentially a canvas API: you get rectangles, lines, triangles and text, and you draw the entire grid yourself. That rewrite (my first merged PR of the project) opened the door for everything that came after.
score of the imgui debugger
What the score window does today:
Sprite spans: consecutive frames where a channel holds the same sprite are drawn as one continuous bar with a start circle and an end square, exactly like Director drew them. Computing these spans means comparing every sprite against its neighbors across the whole score, so the result is cached per movie.
Display modes: the cells can show the cast member name, the behavior script, ink type, blend, location, or an extended multi-row view that shows all of them at once.
The main channels: tempo, palette, transition, and the two sound channels get their own rows above the sprite grid, again matching the original tool.
Navigation: horizontal and vertical scrolling (including mouse wheel), frame labels above the ruler, a playhead that tracks the current frame, and a center button that snaps the view to the playhead.
Interaction: clicking a cell selects the sprite and shows its details in an inspector strip (position, ink, blend, bounding box, flags), and double-clicking a frame jumps the movie there. That last one is dangerously fun.
score in the original director 4
The Cast windows
The cast is Director’s asset library: bitmaps, text, sounds, palettes, film loops, scripts, all numbered members. DT has a Cast browser with list and grid views, type filters, and thumbnails rendered from the actual cast member data, plus a Cast Details window that shows every property of a selected member, organized the same way Director’s own property dialogs were.
Some pieces of this I am particularly happy about:
The film loop viewer. A film loop is an animation packaged as a cast member, and internally it has its own miniature score. So the details window renders a miniature score grid for it, with its own playhead and frame stepping, plus thumbnails of the sprites in the current frame.
Sound playback. Sound cast members get play and stop buttons, sample rate and channel info, and a table of cue points. The preview plays through the engine’s own sound manager on a reserved channel, so what you hear is what the game would play.
The image viewer. Clicking a bitmap or text member opens a dedicated viewer with zoom, pan, fit-to-window, and for text members, a tab showing the raw text with a copy button. Sounds trivial, but when you are comparing a rendered bitmap against a reference screenshot pixel by pixel, zoom and pan stop being luxuries.
mini filmloop viewer in the cast details window
Scripts: reading decompiled Lingo
Director movies do not ship with Lingo source code, they ship compiled bytecode. DT shows you readable Lingo anyway, courtesy of LingoDec, a decompiler that reconstructs an AST from the bytecode. The script windows walk that AST and render it with syntax highlighting: keywords, builtins, literals, comments, each in their own color, with a bytecode view one toggle away.
And the scripts are not just text. Handler calls are links, click one and you jump to its definition. Variables have an eye icon, click it and the variable is added to a watch list. Each line has a breakpoint gutter.
The navigation used to be one floating window per handler, which collapsed the moment two scripts from different cast libraries shared a member number, since the windows were keyed by that number. I replaced it with a single Scripts window that works like a browser: an ordered history, back and forward buttons, and a dropdown of everything you have visited. Go-to-definition pushes onto the history, back pops you out.
the scripts window
Breakpoints plug into the Lingo interpreter itself. When execution pauses, the Control Panel offers step over, step into, and step out, implemented as small predicate functions that the interpreter calls after each instruction to decide whether to keep running.
Here is the entire step-over logic, to show how small these predicates are: The interpreter calls this after every instruction while running. Step into and step out are the same idea with the conditions changed: step into pauses on any line change or callstack change, step out only when the callstack gets shorter. The debugger does not drive the interpreter, it just answers “should we stop here” when asked.
The Execution Context window shows the call stack per engine window, and clicking a stack frame opens that handler at the paused line.
movie paused at a breakpoint
Finding things: Search and the Windows panel
A Director game can contain hundreds of scripts across multiple cast libraries and a shared cast. The Search window greps them all, with modes for handler names, variable names (properties, arguments and globals), and full script bodies, the last one by decoding the compiled bytecode instruction by instruction. Results open in the script browser, and the matched text gets highlighted in the rendered script.
The Windows panel came out of debugging multi-window games (Director movies can open other movies in windows, and yes, that is as messy as it sounds). It lists every loaded window with its movie, play state and frame position, and below that, every .DIR file found in the game directory, click one and the engine navigates to it. That turned out to be the fastest way to explore a game’s movies one by one.
the search window
Two more windows deserve a mention here. The Vars window shows every global, local and property variable live, with changed values highlighted, and any variable can be added to a watch list that logs every write along with the script that did it, which is how you catch the question “who keeps resetting this flag”. And the Archive window is a raw resource browser: every chunk in the movie file, viewable as a hex dump, for the days when the bug is below the level of sprites and scripts entirely.
The stamp snapped back on drop, so: open the Score window and find which channels the stamp and slot live on. Click the slot’s sprite, see it script in the inspector, click through to the Scripts window and read the decompiled mouseUp handler.
Set a breakpoint on it, drag a stamp in the game, and watch the breakpoint never fire.
That single observation, visible in seconds, is the whole bug. The rest was C++.
Everything breaks, including debuggers
A recurring theme this summer: the debugger observes a live engine, and live engines change under you. Movies get switched, casts get destroyed, windows get closed, and every raw pointer the debugger cached becomes a landmine. A good chunk of my June work was a sweep through the whole debugger fixing null dereferences, out-of-bounds accesses, stale pointers and memory leaks, several of which I found by reading the code, looking at crash backtraces etc. and asking about every stored pointer: who deletes this, and does the deleter know we kept a copy?
That exercise changed how I write the feature code too. It is one thing to be told “don’t cache raw pointers to engine objects”, it is another to watch your own cast details window explode because the movie you were inspecting no longer exists.
None of this happened in a vacuum. Every one of these PRs went through review, and the pattern of feedback shaped the debugger more than any single feature: sev pushing back on fixes that need rework, and me reflecting on the review to make the code better.
What is left
DT is genuinely useful today, I use it daily to debug the Gus games, but there is plenty on the wishlist like making it more bullet proof, finding edge cases, adding new features.
If you want to try it: build ScummVM with ImGui support, add --debugflags=imgui to any Director game, and press Ctrl+2 through Ctrl+4 to toggle the main windows.
Things worth knowing on day one: Ctrl+F1 toggles mouse capture, so your clicks stop reaching the game while you arrange windows (hold Shift to click through temporarily); debugger windows can be dragged entirely outside the main ScummVM window if multi-viewport is enabled in Settings; and there is a light theme in Settings for people who debug in daylight. Bug reports welcome, I have become quite good at reading the crashes.
For anyone who wants to hack on DT, here is a map of engines/director/debugger/:
debugtools.cpp / debugtools.h: the orchestrator. Owns the ImGui lifecycle (onImGuiInit, onImGuiRender, onImGuiCleanup), the main menu bar, the keyboard shortcuts, and the theme definitions. Also home to the shared helpers everything else leans on: the texture cache for cast member thumbnails, toImGuiScript() for turning a handler into something renderable, and the script context lookups.
dt-internal.h: the shared state. One big ImGuiState struct that remembers which windows are open, current selections, script history, search results, cached vars, themes, everything that has to survive between frames. If two windows need to talk to each other, they do it through this struct.
dt-cast.cpp: the Cast browser window. List and grid views, type filters, name filter, thumbnails.
dt-castdetails.cpp: the Cast Details window with per-type property tabs (bitmap, text, rich text, shape, sound, film loop), the film loop mini-score viewer, and the image viewer with zoom and pan.
dt-controlpanel.cpp: playback controls (play, stop, rewind, frame stepping) and the Lingo stepping buttons. The step over/into/out predicates that the interpreter consults live here.
dt-lists.cpp: the grab bag of list windows: Vars (globals, locals, properties), Watched Vars with the write log, the Breakpoints list, the Archive resource browser with a hex view, and the Windows panel.
dt-score.cpp: the big one. The Score window (grid, spans, ruler, playhead, main channels, sprite inspector) and the Channels window showing the live state of every channel in the current frame.
dt-scripts.cpp: the Scripts window with its browser-style history, the Functions list, and the Execution Context window with per-window call stacks.
dt-script-d4.cpp: the renderer for decompiled Lingo. Walks the LingoDec AST and draws syntax-highlighted code with the breakpoint gutter, current-statement marker, and clickable handler calls. Used for Director 4+ bytecode.
dt-script-d2.cpp: the same job for older movies (D2/D3), which ScummVM compiles from source itself, so this walks ScummVM’s own AST instead of LingoDec’s.
dt-search.cpp: the Search window: handler names, variable names, and full body search by decoding bytecode.
dt-save-state.cpp: layout persistence. Serializes open windows, ImGui window positions, and settings to JSON so your debugging setup survives restarts.
Welcome back, happy to be writing back after so long. I’ve got myself on the work again and there’s 2-3 days of progress I want to brief about. But before that, I must inform that the initial PR for iBASS support has been merged(it was merged while I was away), which means that now you can play iBASS on the debug builds. All you need to arrange are the game files. Continuing the efforts of porting, I implemented the text chooser(the PR is currently opened). But first let’s understand what exactly is the text chooser.
Text Chooser
See the questions at the top. When we talk to the NPCs, a list of questions in this form appears. We have to select a dialogue from this list.
This is how it works.
The PR is currently opened. Once it gets merged, you’ll be able to use this feature.
The silent killer
Day before yesterday, while I was implementing the text chooser, the game crashed on starting. I was lucky that I had run that time with gdb so I recorded the backtrace-
Thread 1 “scummvm” received signal SIGSEGV, Segmentation fault.
0x000055555924128a in READ_UINT16 (ptr=0x55555ed36000) at ./common/endian.h:209
209 return ((const Unaligned16 *)ptr)->val;
(gdb) bt
#0 0x000055555924128a in READ_UINT16 (ptr=0x55555ed36000)
at ./common/endian.h:209
#1 Sky::Disk::getFileInfo (this=0x55555e4a7640, fileNr=60600)
at engines/sky/disk.cpp:310
#2 0x0000555559240c60 in Sky::Disk::fileExists
(this=0x55555e4a7640, fileNr=60600) at engines/sky/disk.cpp:169
#3 0x000055555922e5c6 in Sky::SkyEngine::init (this=0x55555e48dec0)
at engines/sky/sky.cpp:462
#4 0x000055555922f0f1 in Sky::SkyEngine::run (this=0x55555e48dec0)
at ./engines/sky/sky.h:130
#5 0x00005555560e808c in runGame
(enginePlugin=0x55555d3d2f60, system=…, game=…, meDescriptor=0x0)
at base/main.cpp:328
#6 0x00005555560ea70d in scummvm_main (argc=1, argv=0x7fffffffde28)
at base/main.cpp:840
#7 0x00005555560e4d84 in main (argc=1, argv=0x7fffffffde28)
at backends/platform/sdl/posix/posix-main.cpp:56
the getFileInfo function reads from a variable named _dinnerTableArea that is never written to in iBASS since iBASS doesn’t have a separate sky.dnr file.
So, the game starts successfully most of the time because it contains garbage. If it doesn’t, the game crashes. To fix this, I used the getEntry() method.
This week was about closing out a drag-and-drop bug that had been bothering me, building test movies in real Director 4, and finally facing the AddressSanitizer. Let me walk through what happened.
The Post Office Bug
The centerpiece of the week. In Gus Goes to Cyberopolis, the post office letter minigame was broken: dragging a stamp onto the letter’s slot made it snap back to its tray every time, making the minigame unwinnable.
Some quick background for this one. A Director movie is composed of sprites, visual objects placed on numbered channels, and each sprite can have a script attached that reacts to events like mouseDown and mouseUp. Lingo (Director’s scripting language) also has a property called the clickOn, which returns the channel number of the sprite the user last clicked.
The game’s logic is simple: the stamp’s script handles mouseDown and starts the drag, and the slot’s script handles mouseUp and places the stamp. On release, the slot’s script asks the clickOn which channel was involved and checks whether it holds an empty slot. So for a drop to work, two things must happen when the mouse is released: the mouseUp event must be delivered to the sprite under the mouse (the slot, not the stamp), and the clickOn must return the slot’s channel.
Neither was happening in ScummVM. For Director 4 movies, mouseUp was being delivered using the sprite remembered from the original mouseDown, so the stamp’s script received the mouseUp. The stamp has no mouseUp handler, so the event fell through to the frame script, whose fallback logic snaps the stamp back to the tray. And the clickOn still pointed at the stamp’s channel from the original click.
Understanding this took a detour through Director’s message hierarchy, events are offered to the sprite’s script first, then the cast script, the frame script, and finally the movie script, with each level able to stop or pass the event along. Reading the game’s four scripts against a debugger session made it click.
The fix: deliver mouseUp to the sprite currently under the mouse for Director 4 movies, and update the clickOn when mouseUp lands on a sprite, so drop-target scripts can identify the target channel. Stamps now stick to letters.
NOTE: the fix is not final yet. Further discussion with sev will decide its final shape.
Building the Regression Test
Sev’s condition for the fix was tests, so I made some test movies in Director 4. The test suite in the director-tests repo uses a plugin (an “XObject” in Director terms) that can inject input events, move the mouse, press and release the button, and assert on the order in which handlers run, using a global counter.
The new test places two sprites on stage, presses the mouse on sprite 1, moves to sprite 2, and releases. Sprite 1’s script asserts it received the mouseDown; sprite 2’s asserts it received the mouseUp. Without the fix, sprite 2’s handler never fires and the assert count comes up short; with the fix, everything passes.
My first version attached the handlers to the cast members instead of the sprites, and the test failed for the wrong reasons, the handlers need to be sprite scripts to exercise the exact dispatch path the fix touches. I also added a screenshot call to last week’s text wrapping test, so that fix now has visual regression coverage against a reference image captured from real Director 4.
Film Loop Position Shift
A film loop is a Director cast member that packages a small animation so it can be placed on a channel like any static image. In the Kooky Carnival’s shooting gallery, animal sprites jumped to the wrong position when clicked.
When a script swaps a sprite’s image for another cast member at runtime, the new member may use a different registration point, the anchor that decides how the image is positioned. Normal bitmaps anchor at the top-left; film loops anchor at their center. ScummVM wasn’t adjusting the sprite’s position for that difference, so the sprite visually shifted by half its size on swap.
The fix saves the sprite’s on-screen bounding box before the swap and adjusts its position afterward, so it stays put. I had pushed a similar solution a long while ago, but it was in the wrong place. This one works.
What not to do
I had some uncommitted changes sitting on the buildbot server, which broke the imagediff tooling.
A refactor by sev had moved code from imagediff.py into main.py, and two things were left broken. First, main.py imported its config before running the sys.path bootstrap, so the dashboard could not load from a fresh start at all (ModuleNotFoundError: config). Second, screenshot_diff.py still imported from the old imagediff/imagediff.py module that no longer existed, so every ScreenshotDiffStep failed.
The fix moved the bootstrap before the config import, pointed the diff step at the new module, and cleaned out leftover debug prints and dead code. Merged.
Fortunately the uncommitted changes on the server were trivial and I was able to revert them.
Lesson learnt: do not leave unfinished work on prod servers (-_-) (use git, github).
My First Use-After-Free
While testing one of the Cyberopolis movies, ScummVM crashed when switching movies, but only in my AddressSanitizer build. This was my first time actively reading an ASAN report. As I was looking into this, I asked sev and after looking at the backtrace he found 2 commits which were the likely cuplrits.
The older commit, related to some changes in movie cast members, was the culprit. As this is a difficult bug, this will be taken care of by sev.
The visual debugger
Some DT changes have been made locally, but will finalize them and push the commits soon. Mostly bugs and crashes, nothing very interesting. And the DT blog is almost ready. Wasn’t able to work on it for a few days. Will publish in a day or two.
Next up:
– work on an animation speed bug
– continue on gus bugs
Hello and welcome back! This is Week 6 of my GSoC journey, and I’m excited to share that I’ve finally completed the Dungeon Master engine!
Fixing the Endianness Problem
As I mentioned in the last blog, using READ_LE_UINT16 and WRITE_LE_UINT16 macros had a deeper issue — loadDungeonFile() reads Big-Endian file data and stores it into _thingData as native-endian uint16s, so on a Big-Endian machine the whole setup breaks regardless of the macro fix.
So I spent the first half of this week replacing those byte offset macros by parsing the file data directly into respective arrays of structs at load time. This involved removing all raw byte-to-struct pointer casting (e.g., (Door *)rawDat) from the codebase and updating the file loading and saving routines to read and write fields one at a time using stream operations like readUint16BE and writeUint16BE.
Uncovering Hidden Bugs
These changes also brought some new freezes and crashes to the surface — bugs that were silently hiding behind the old unsafe code. Raw pointer arithmetic was allowing silent reads and writes to out-of-bounds memory, which switching to Common::Array now catches immediately as crashes or assertions. Unsafe casting was hiding cases where one object type was being read as another, which strict C++ type assertions now catch instantly.
Debugging the Endgame
The endgame sequence had quite a few bugs hiding in it. When you capture the Lord of Chaos and fuse him with The Firestaff, the game unlinks the fluxcage — but in fuseSequence(), curThing was never being reset after that, causing the loop to run forever.
When the Lord of Chaos was turned back to normal, the message displayed was also corrupted — wrkString was declared outside the loop so it kept accumulating characters from previous words, and a stray \0 append was preventing it from reading past the first word. Moving wrkString inside the loop and removing \0 fixed the issue.
Another text bug had only the second row showing up in the message area — the first row was being cleared before it could scroll up. createNewRow() was clearing the line buffer before the scroll animation could finish, so the fix was to wait in a small delay loop until _isScrolling is false before proceeding.
Beyond that, I also added support for returning to the launcher after closing the game, along with other small fixes to get the engine to a solid, playable state.
Crash When Renaming Champion in the Hall of Champions
Clicking outside the character select table during champion renaming was calculating an invalid character index from out-of-bounds coordinates, causing a crash. The fix was straightforward — enabling a bounds check that was previously disabled, so clicks outside the table are now simply ignored.
Implementing Extended Saves
I also implemented extended saves for the DM engine, allowing the game to make use of ScummVM’s extended save functionality.
That was it for this week! It’s been a long road getting the DM engine to this point, but it’s rewarding to finally see the work of the previous contributor and Strangerke pay off after 10 years. You can find the previous contributor’s blog here.
Thanks to Sev for helping me throughout this.
I’ll see you in the next blog as I dive into a new engine. Until then, bye! 👋
Last week ended with the European Amiga version of Kult running almost perfectly, and a promise: next up, the US release. In America, the game shipped as Chamber of the Sci-Mutant Priestess, published by Draconian, and this week was all about making that version boot and play too.
Same game, different executable
My hope was that the US build would just be the EU one with translated text files. It wasn’t. The Draconian build lays out the KULT executable completely differently:
Every static resource lives at a different offset. On the EU side, I had a table of file offsets for the resources embedded in the executable (palettes, icons, zone data…). The US executable shifts them around non-uniformly, so I couldn’t just add a constant — I had to reverse-engineer the US binary and rebuild the whole offset table entry by entry. The good news: once located, 8 of the 12 embedded resources turned out to be byte-identical to the EU ones; only ZONES, TEMPL, CARAC, and ICONE actually differ.
The English text banks are jammed straight into the executable, completely abandoning the neat separate files the EU release used. This meant writing a different extraction path just for the US text.
The filenames are lowercase.Normally, this would be an immediate problem on case-sensitive file systems like Linux. Thankfully, ScummVM’s Common::File API handles case-insensitivity out of the box, which saved me from having to write any extra fallback logic!
A different welcome screen
The US version also greets you differently: it shows an intro.pia title screen before the usual pres.bin presentation. It’s a small detail, but until the engine knew about it, the game wouldn’t even get past boot.
Zone Scan, the Amiga way
While testing, I also finished the Amiga version of the Zone Scan psi power. The Amiga renderer draws it differently from DOS: the effect applies a dedicated palette delta that tints the room green while the scan line sweeps across the screen. Getting the line itself right took one more fix — the sweep works on chunky pixels now, so the line width and the inversion effect had to be adapted from the original planar code.
Detection entries
With both variants playable, I added proper detection entries for the Amiga EU and US releases. ScummVM now recognizes all of them straight from the launcher.
Looking back at these past two weeks, I am incredibly happy to see the Amiga versions finally fully animated and playable. Building the Amiga support from absolute scratch was a massive, daunting challenge, and I honestly couldn’t have reached this milestone without the immense help and guidance from my mentor. Seeing these versions breathe and run flawlessly makes all the heavy lifting worth it!
Next week
While all this was happening, sev ran static analysis over the engine and sent me a nice stack of Coverity and PVS-Studio reports. While chasing those, I found a bug that wasn’t in my engine at all, but in ScummVM itself. More about that (and about a monster that refused to survive a save/load cycle) in the next post!).Stay tuned!


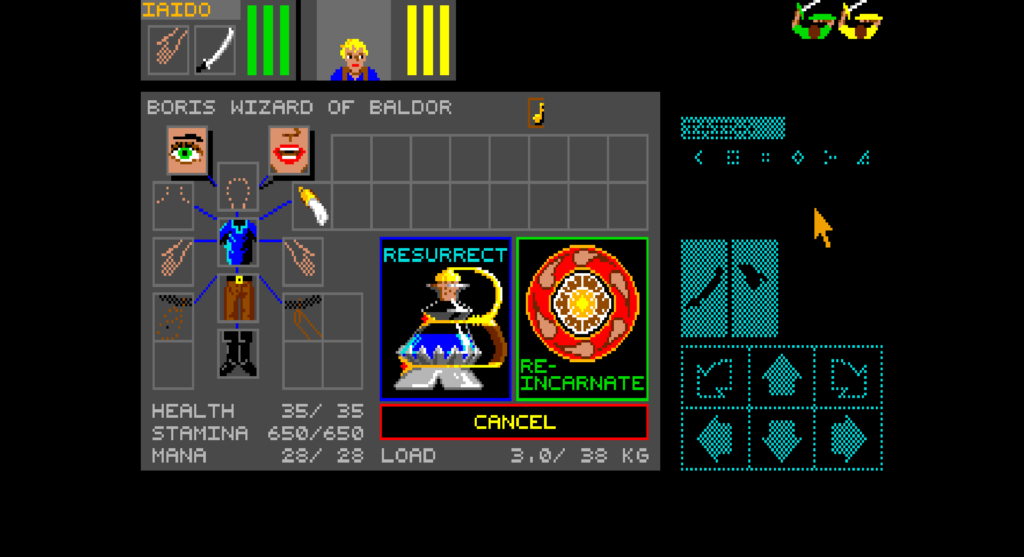
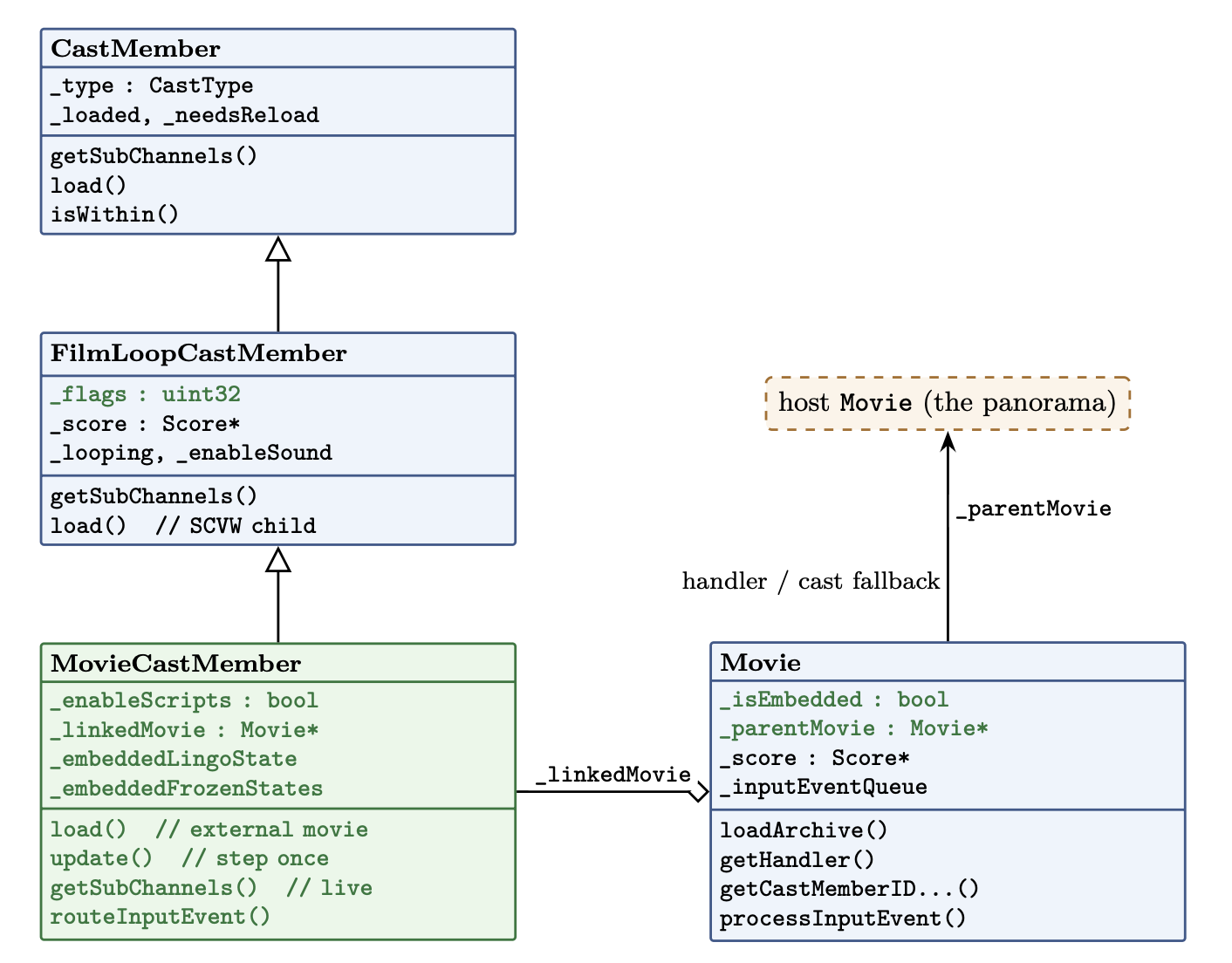
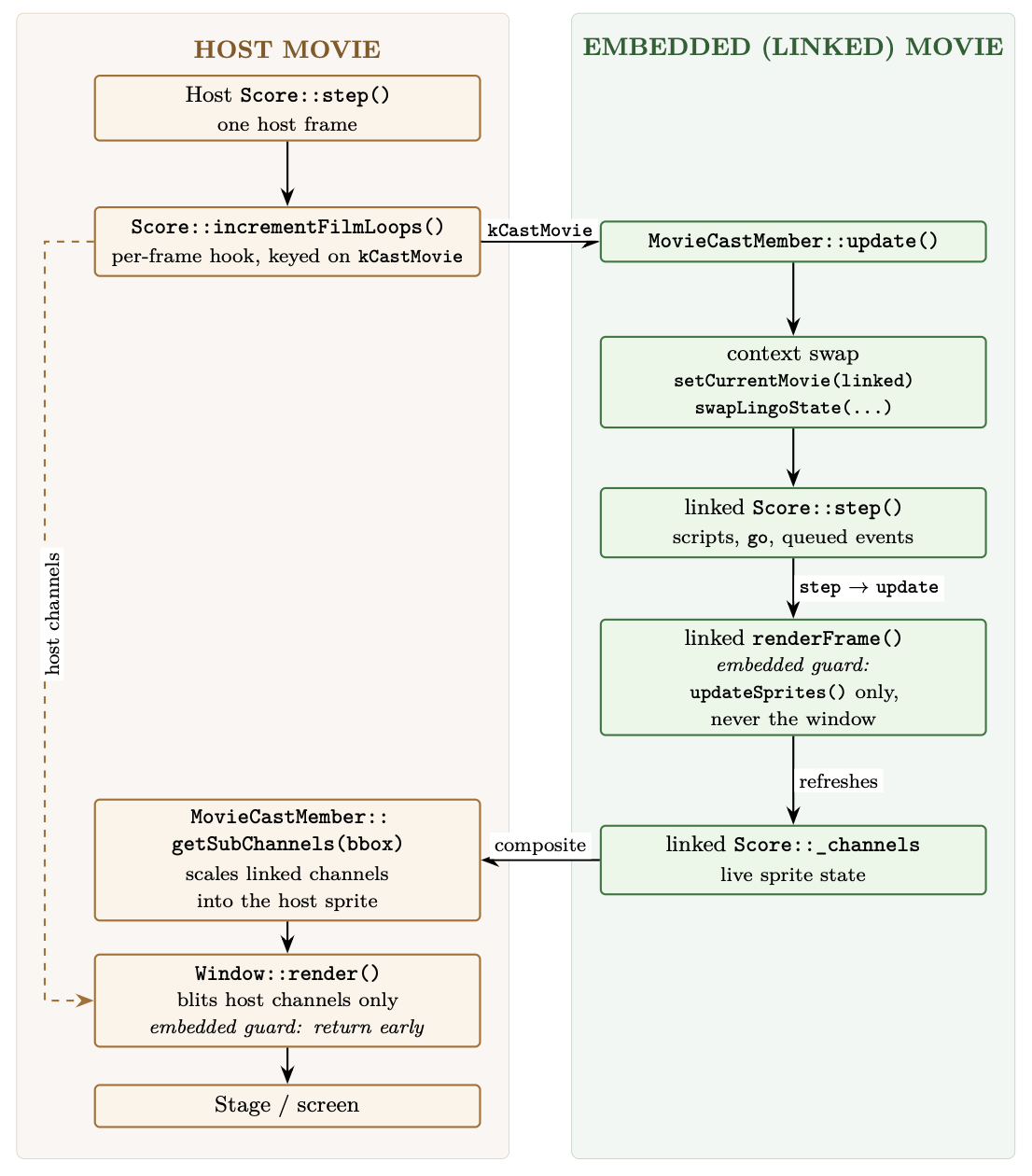
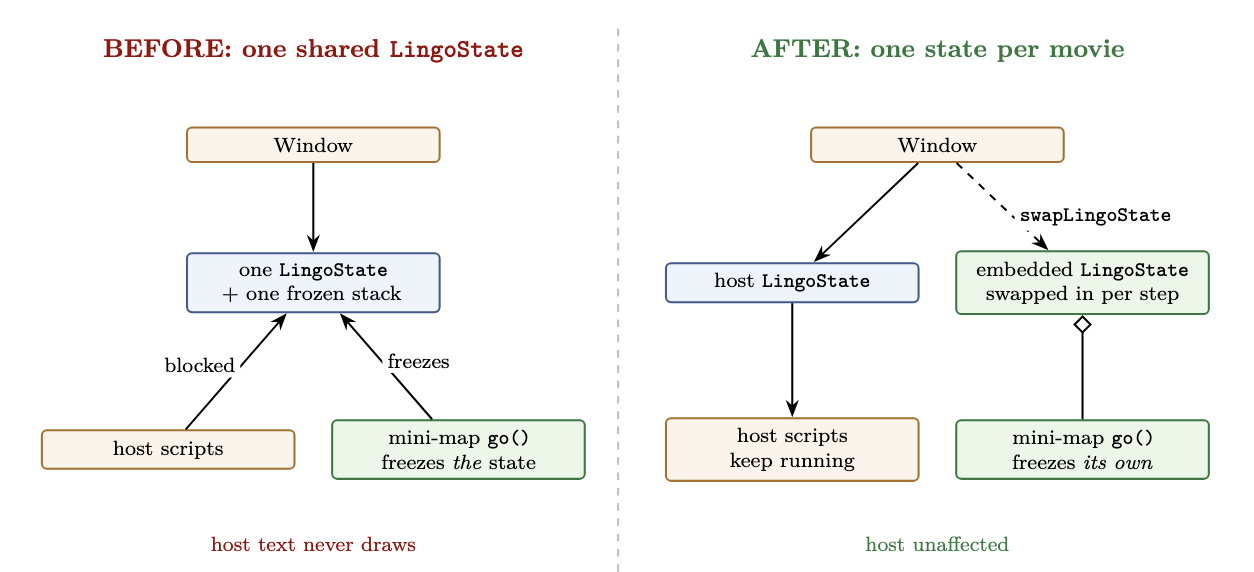
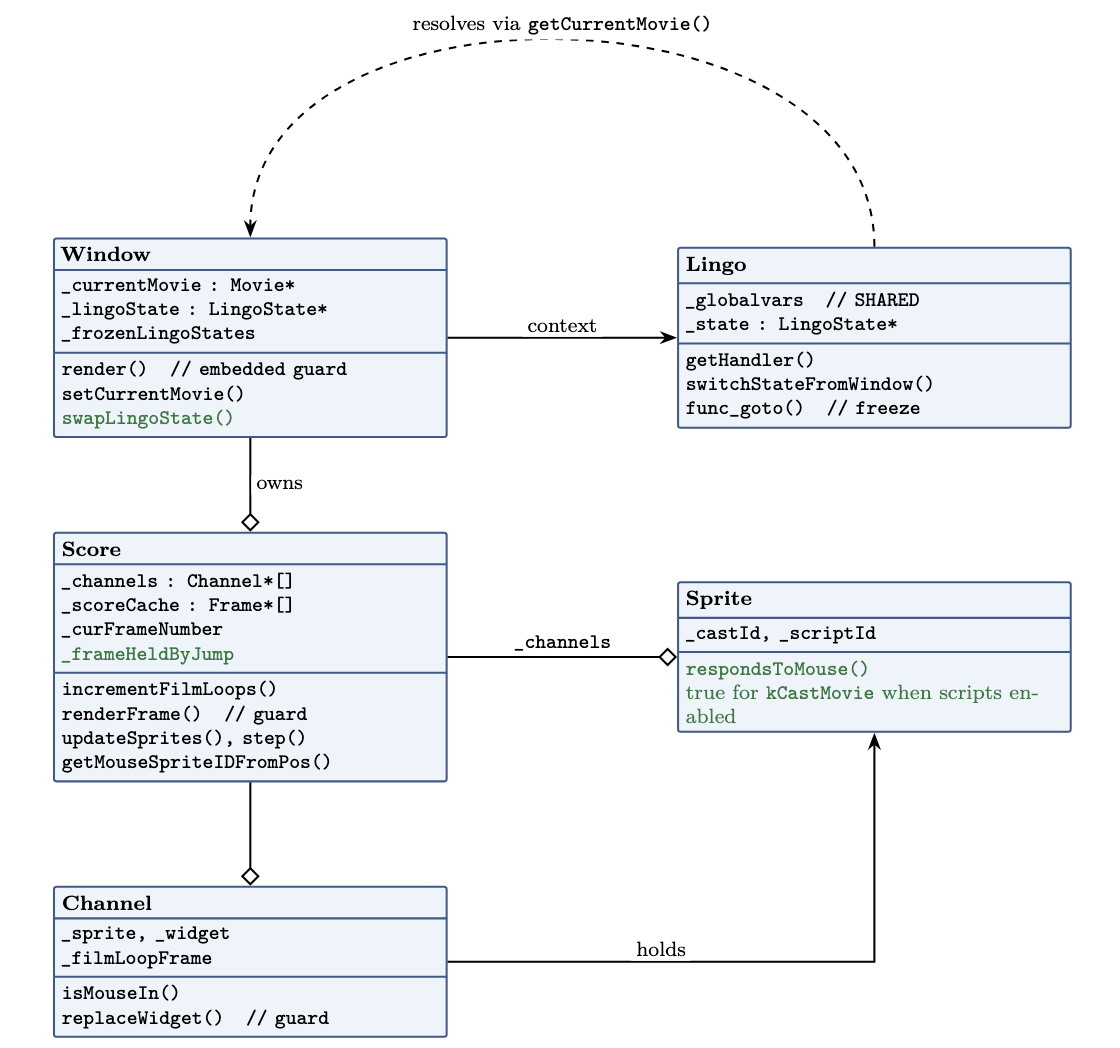
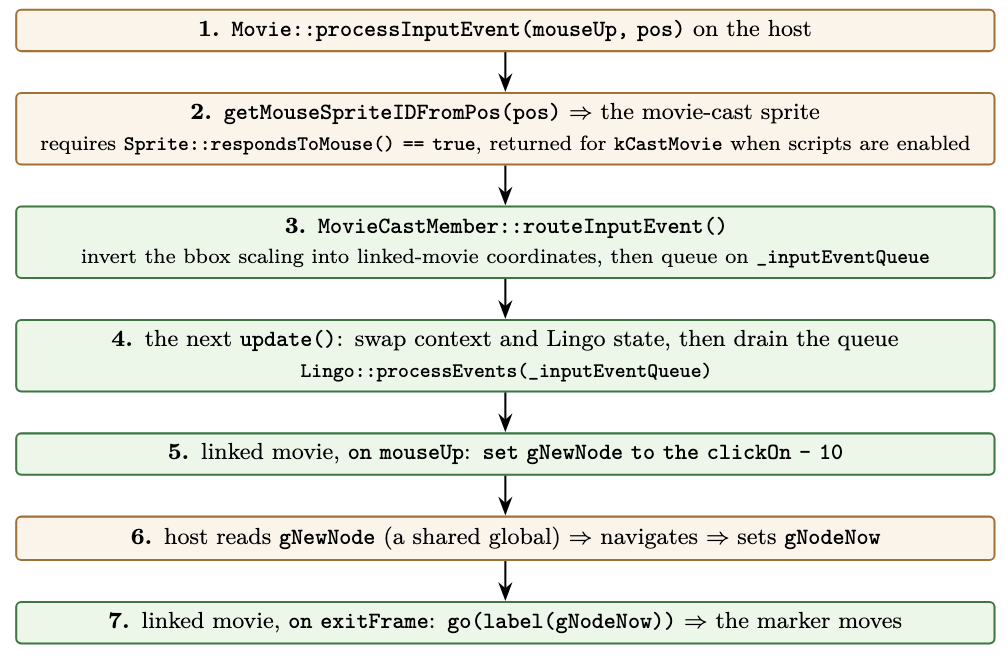
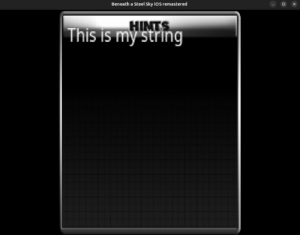




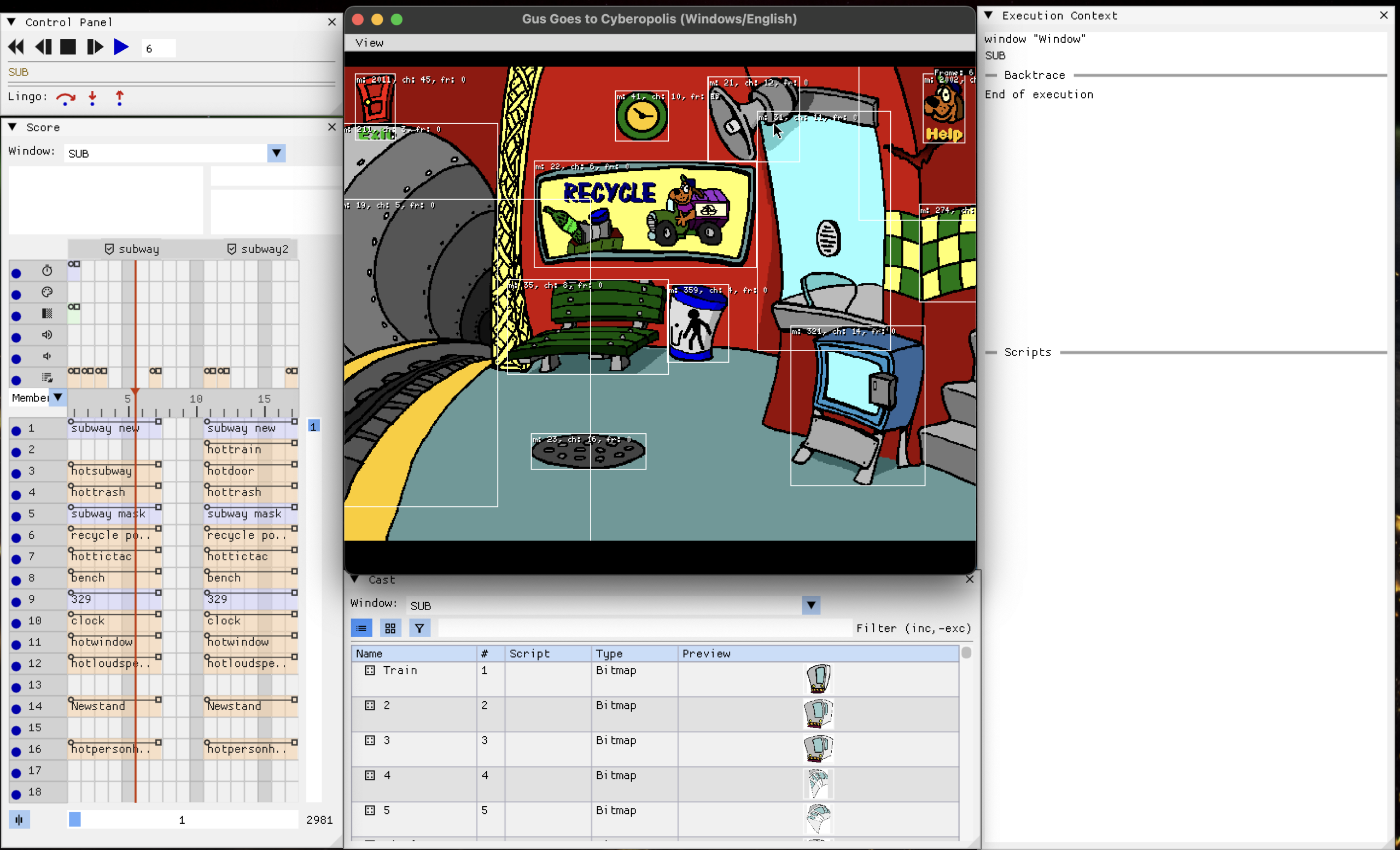
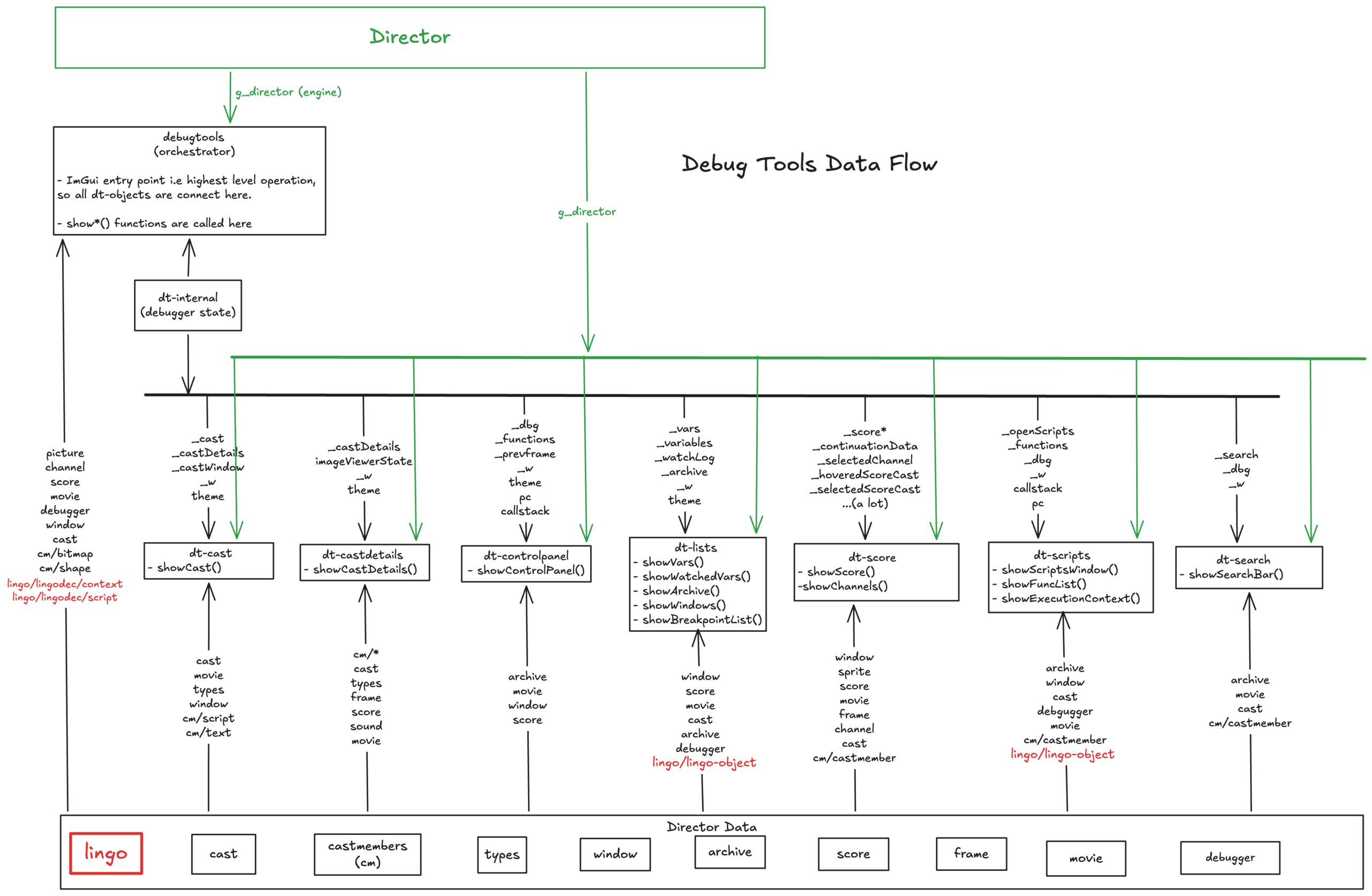
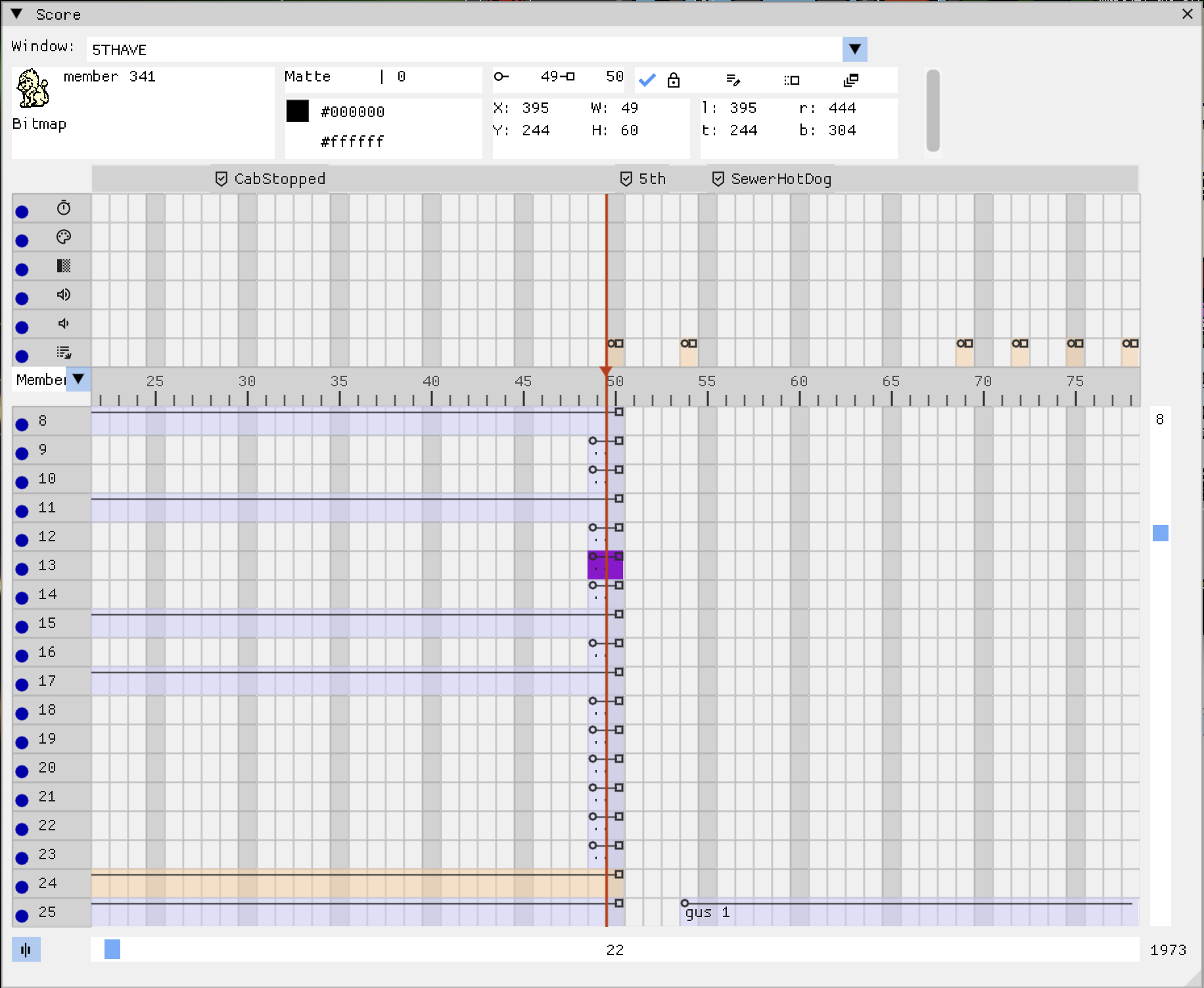
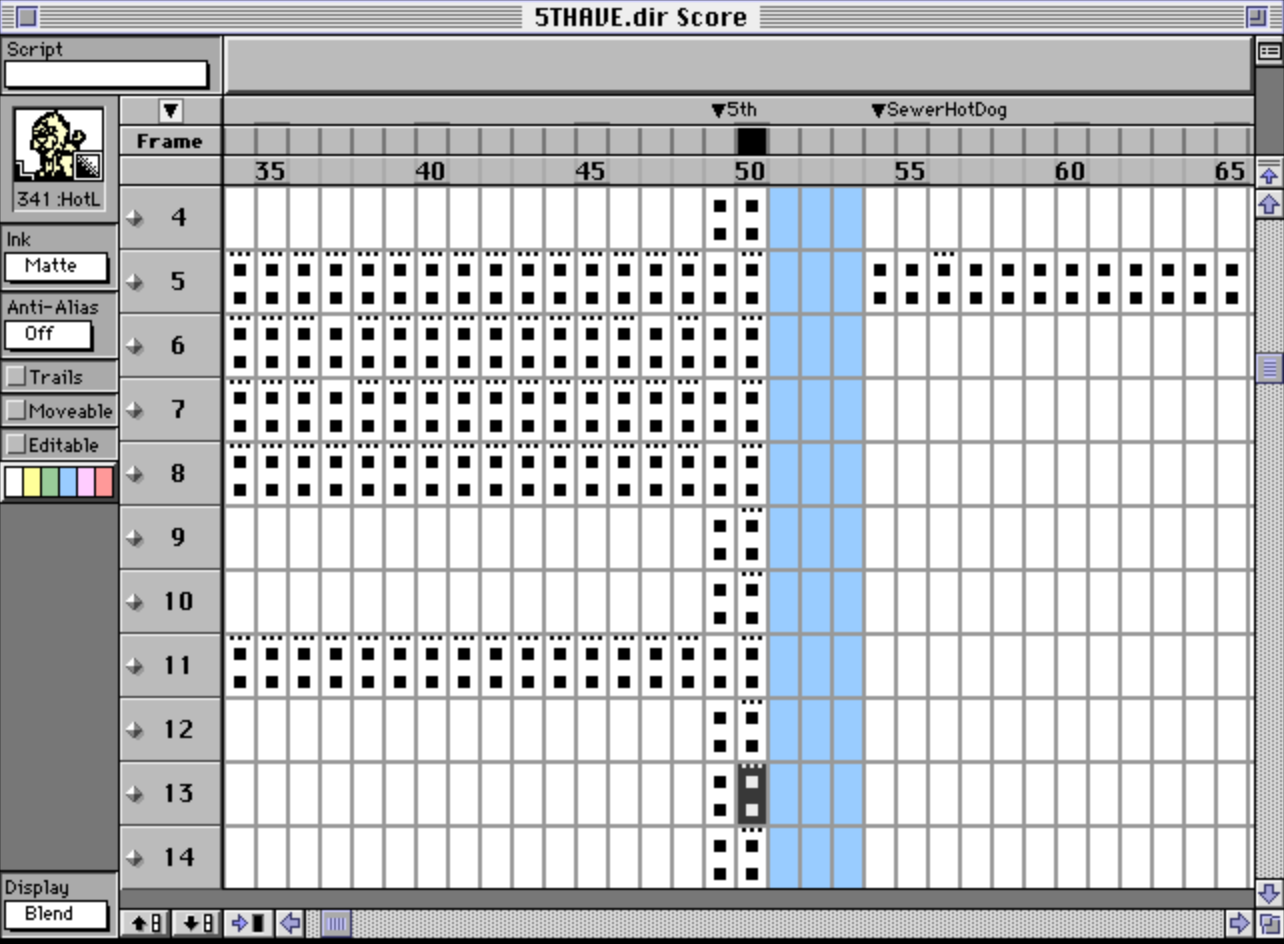
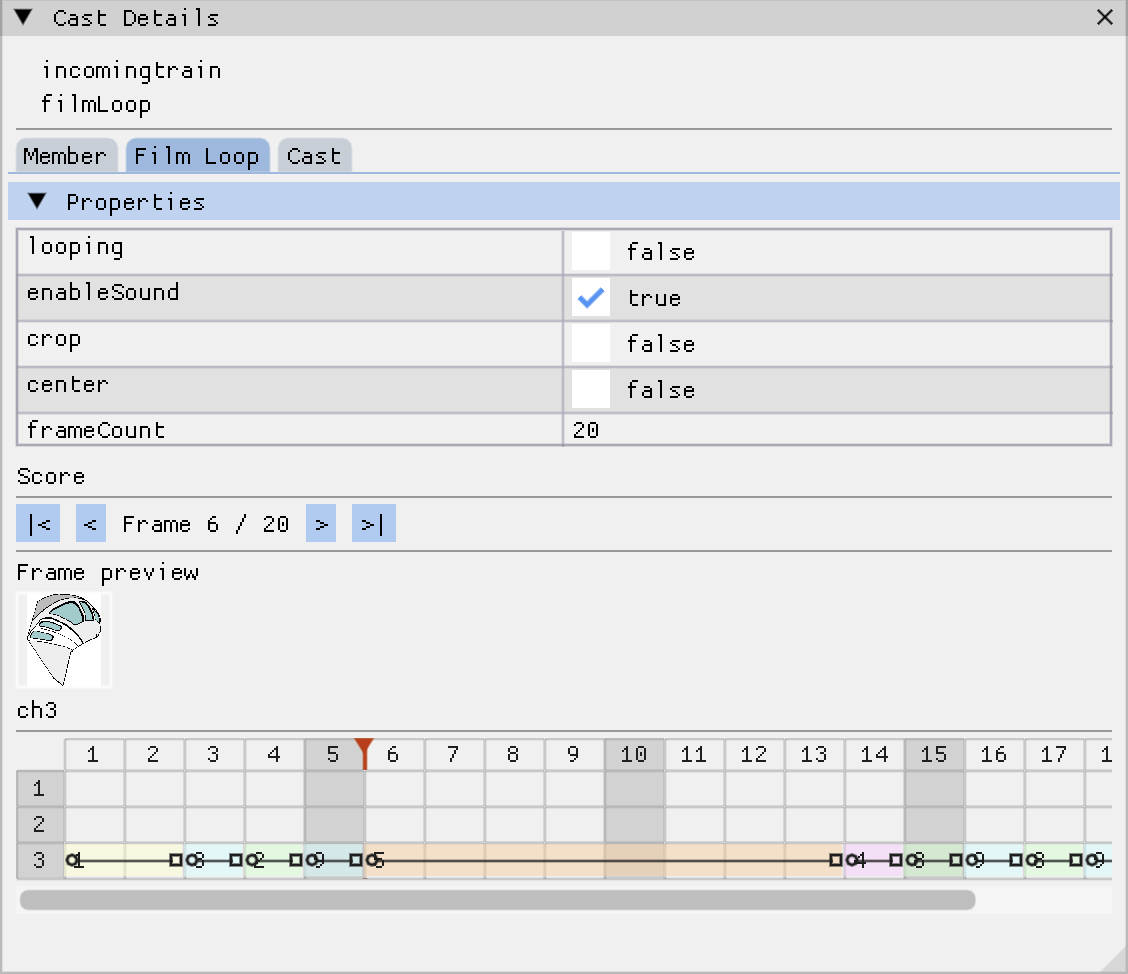
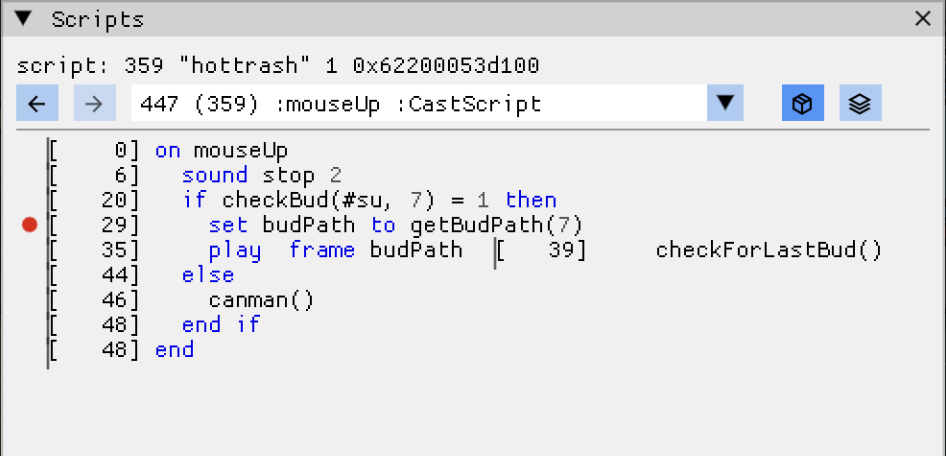
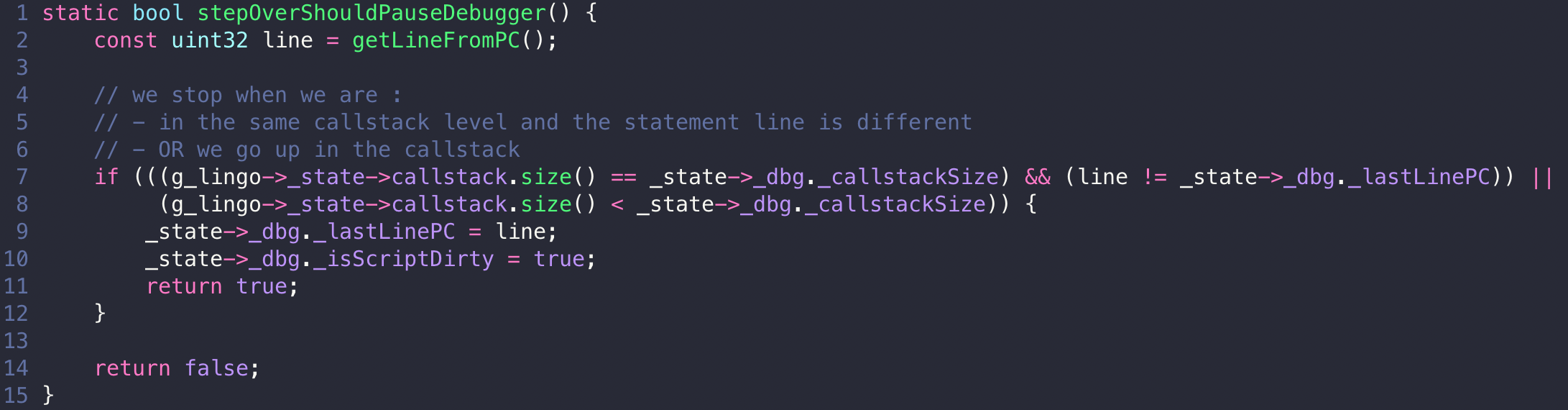 The interpreter calls this after every instruction while running. Step into and step out are the same idea with the conditions changed: step into pauses on any line change or callstack change, step out only when the callstack gets shorter. The debugger does not drive the interpreter, it just answers “should we stop here” when asked.
The interpreter calls this after every instruction while running. Step into and step out are the same idea with the conditions changed: step into pauses on any line change or callstack change, step out only when the callstack gets shorter. The debugger does not drive the interpreter, it just answers “should we stop here” when asked.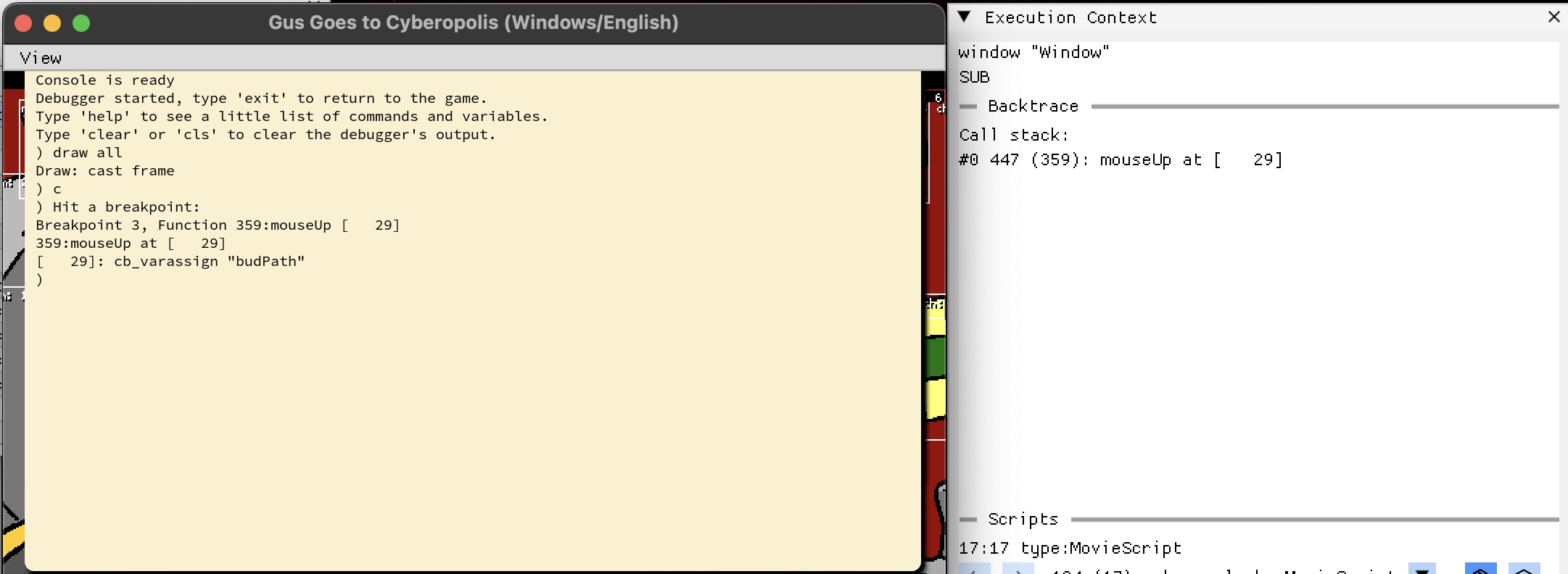
 See the questions at the top. When we talk to the NPCs, a list of questions in this form appears. We have to select a dialogue from this list.
See the questions at the top. When we talk to the NPCs, a list of questions in this form appears. We have to select a dialogue from this list.
